问题背景
一致性有很多种
- 强一致性:保证写入后立即可以读取
- 弱一致性:在系统写入后,不承诺立即可以读到写入的值,也不承诺多久之后数据能够达到一致,但会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一致状态
- 最终一致性:最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态
缓存可以提升性能、缓解数据库压力,使用缓存也会导致数据不一致性的问题
缓存系统的数据一致性通常包括持久化层和缓存层的一致性、以及多级缓存之间的一致性,这里讨论是前者。持久化层和缓存层的一致性问题也通常被称为双写一致性问题。
实现原理
引入 Cache 之后,延迟或程序失败等都会导致缓存和实际存储层数据不一致,下面几种模式减少不一致风险
- Cache-Aside Pattern,即旁路缓存模式
- Read-Through/Write-Through,读写穿透模式
- Write behind,异步缓存写入模式
Cache-Aside
读模式
当缓存命中则直接返回,否则从数据库读取数据并更新缓存
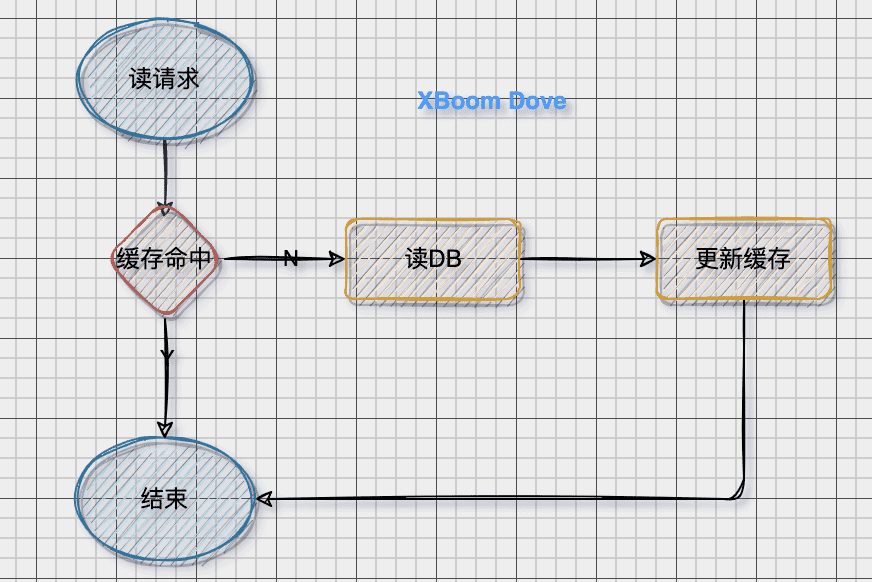
写模式
首先更新数据库,然后删除缓存
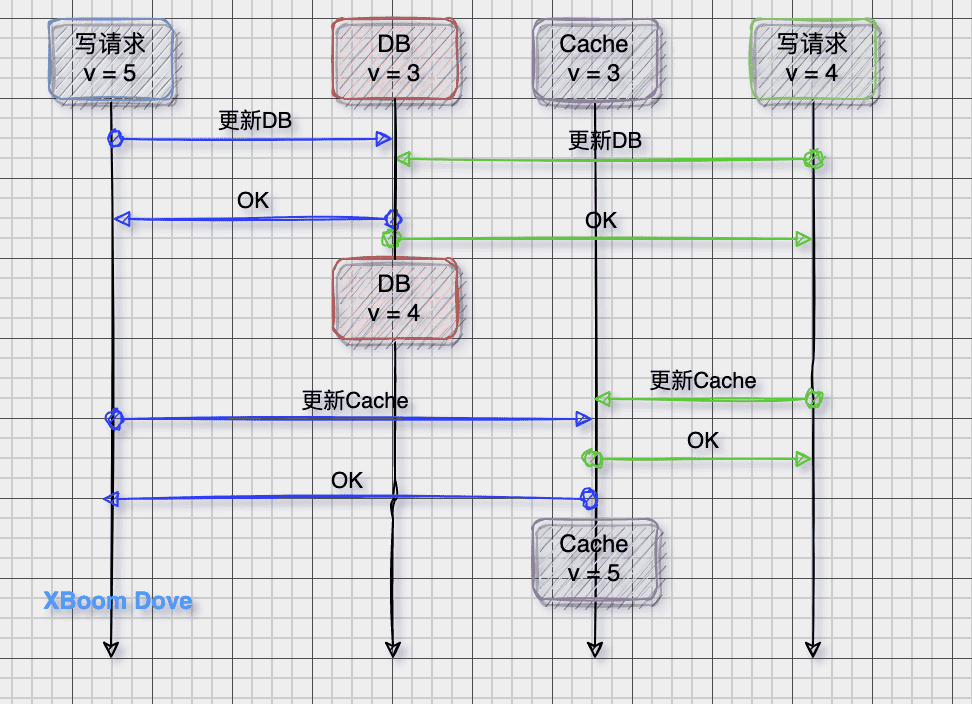
问题1:为什么是删除缓存,而不是更新缓存
- 如果缓存需要通过大量的计算(联表查询更新),那么更新缓存会是一笔不小的开销
- 另外如果写操作比较多,可能存在刚更新的缓存还没有读取就又要更新的情况(称为缓存扰动),所以此模式适用于读多写少的模式
- 等到读请求未命中再去更新,符合懒加载思路
- 并发更新可能导致缓存落后与数据库,读请求读到的仍然是旧缓存
问题2:为什么是先更新数据库,而不是先删除缓存
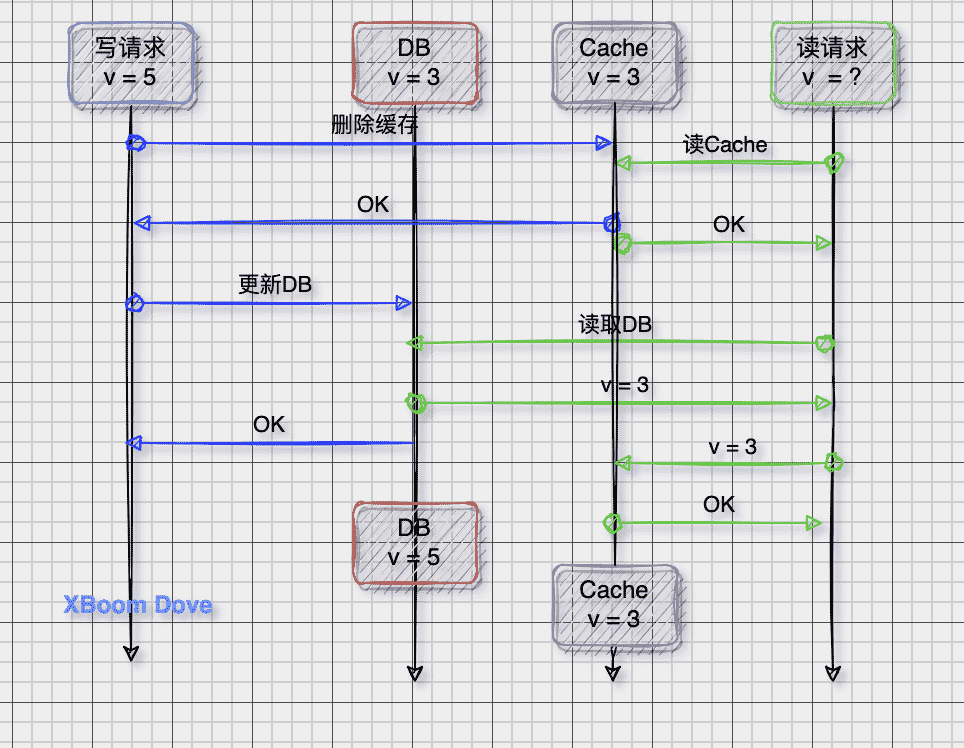
数据库查询请求往往比更新请求更快,可能这种异常更容易出现
Read/Write Through
读模式
当缓存命中则直接返回,否则从数据库读取数据并更新缓存
Read/Write Through模式中,服务端把缓存作为主要数据存储。应用程序跟数据库缓存交互,都是通过抽象缓存层完成的
写模式
Write Through模式在发生Cache Miss的时候,只会在读请求中更新缓存。
-
写请求在发生Cache Miss的时候不会更新缓存,而是直接写入数据库;
-
如果命中缓存则先更新缓存,由缓存自己再将数据写回到数据库中
注意这个时候如果命中缓存,是先更新缓存的。也就说和 Cache-Aside一样存在并发场景下的一致性问题
这个策略的核心原则:用户只与缓存打交道,由缓存组件和DB通信,写入或者读取数据。在一些本地进程缓存组件可以考虑这种策略
Write-Through 存在的缺陷:写数据时缓存和数据库同步,但是我们知道这两块存储介质的速度差几个数量级,对写入性能是有很大影响。那我们是否异步更新数据库
Write behind
Write behind 跟有相似的地方,都是由Cache Provider来负责缓存和数据库的读写。它两又有个很大的不同:Read/Write Through是同步更新缓存和数据的,Write Behind则是只更新缓存,不直接更新数据库,通过批量异步的方式来更新数据库
缓存和数据库的一致性不强,对一致性要求高的系统要谨慎使用。但是它适合频繁写的场景,MySQL的InnoDB Buffer Pool机制就使用到这种模式
延时双删
延时双删主要用于 Redis主从节点的场景,延时的原因是,mysql 和 redis 主从节点数据不是实时同步的,同步数据需要时间。
- 服务节点删除 redis 主库数据
- 服务节点修改 mysql 主库数据
- 服务节点使得当前业务处理
等待一段时间,等 redis 和 mysql 主从节点数据同步成功。 - 服务节点从 redis 主库删除数据。
- 当前或其它服务节点读取 redis 从库数据,发现 redis 从库没有数据,从 mysql 从库读取数据,并写入 redis 主库
注意:
- 延时双删,有等待环节,如果系统要求低延时,这种场景就不合适了。
- 延时双删,不适合“秒杀”这种频繁修改数据和要求数据强一致的场景。
- 延时双删,延时时间是一个预估值,不能确保 mysql 和 redis 数据在这个时间段内都实时同步或持久化成功了
重试保障
方案1:服务自行订阅删除缓存消息
- 更新数据库数据;
- 缓存因为种种问题删除失败;
- 将需要删除的key发送至消息队列;
- 自己消费消息,获得需要删除的key;
- 继续重试删除操作,直到成功
方案2:利用第三方服务删除缓存
- 更新数据库数据;
- 数据库会将操作信息写入binlog日志当中;
- 订阅程序提取出所需要的数据以及key;
- 另起一段非业务代码,获得该信息;
- 尝试删除缓存操作,发现删除失败;
- 将这些信息发送至消息队列;
- 重新从消息队列中获得该数据,重试操作
注意:
- 删除缓存也可能存储缓存击穿的问题
- 在 GoZero8-数据库缓存中中使用共享调用的方式(类似自旋锁)进行数据查询
- 使用方案1进行消息订阅的时候可能出现消息队列也失败的情况
强一致性肯定会有性能影响(比如 raft协议需要等待超过半数节点做出响应),另外强一致性的异常处理
技术内幕
来看看 rockscache 如何解决缓存一致性的,
地址:https://github.com/dtm-labs/rockscache
The First Redis Cache Library To Ensure Eventual Consistency And Strong Consistency With DB.
变量定义
1 | //rockscache client 可选参数 |
lua脚本
使用脚本进行redis操作,lua的好处是一次性执行,执行过程其他脚本或命令无法执行(注意不确定参数)。
这里使用hash进行数据存储,同时保存 key/value 与 key/lock
1 | func (c *Client) luaGet(key string, owner string) ([]interface{}, error) { |
加锁和解锁
1 | //加锁 |
读取缓存
1 | // new a client for rockscache using the default options |
这里也提供了忽略锁的操作
1 | func (c *Client) RawGet(key string) (string, error) { |
强一致性获取
1 | func (c *Client) weakFetch(key string, expire time.Duration, fn func() (string, error)) (string, error) { |
1 | func (c *Client) fetchNew(key string, expire time.Duration, owner string, fn func() (string, error)) (string, error) { |
总结
应该根据场景来设计合适的方案解决缓存一致性问题
- 读多写少的场景下,可以选择采用 Cache-Aside 结合消费数据库日志做补偿 的方案
- 写多的场景下,可以选择采用 Write-Through 结合分布式锁的方案
- 写多的极端场景下,可以选择采用 Write-Behind 的方案
- 可以通过读取 binlog (阿里云canal)异步删除缓存缓存
参考文档
- https://blog.csdn.net/qq_34827674/article/details/123463175
- https://learn.lianglianglee.com/专栏/300分钟吃透分布式缓存-完
- 分布式之数据库和缓存双写一致性方式解析
- Cache-Aside Pattern
- Scaling Memcache at Facebook
- https://www.w3cschool.cn/architectroad/architectroad-cache-architecture-design.html
- https://cloud.tencent.com/developer/article/1932934
- https://segmentfault.com/a/1190000040976439
- https://talkgo.org/t/topic/1505
- https://github.com/dtm-labs/rockscache/blob/main/helper/README-cn.md