什么是MapReduce?
MapReduce是Google提出了一个软件架构,用于大规模数据集的并行运算。
MapReduce通过把对数据集的大规模操作分发给网络上的每个节点实现可靠性;每个节点会周期性的把完成的工作和状态的更新报告回来。如果一个节点保持沉默超过一个预设的时间间隔,主节点记录下这个节点状态为死亡,并把分配给这个节点的数据发到别的节点。
go-zero的MapReduce则借鉴其中的思想,接下来一起看下go-zero是如何应用这一思想的
在微服务中开发中,如果多个服务串行依赖的话那么整个API的耗时将会大大增加。通过什么手段来优化?
传输层面通过MQ的解耦特性来降低API的耗时
MQ通信效率没有grpc高(消息通过MQ服务器进行中转)
业务层面通过Go语言的WaitGroup工具来进行并发控制
实际业务场景中:
如果接口的多个依赖有一个出错,则期望能立即返回且不必等待所有依赖都执行完毕。已经完成的接口调用也应该回滚
多个依赖可能有部分依赖之间也存在着相互依赖,或者上下关系
go-zero的主要应用场景为:需要从不同的rpc服务中获取相应属性组装成复杂对象,比如要查询商品详情:
商品服务-查询商品属性
库存服务-查询库存属性
价格服务-查询价格属性
营销服务-查询营销属性
如果是串行调用的话响应时间会随着 rpc 调用次数呈线性增长,简单场景下使用 WaitGroup 也能够满足需求,但如果要对 rpc 调用返回的数据进行校验、数据加工转换、数据汇总呢?
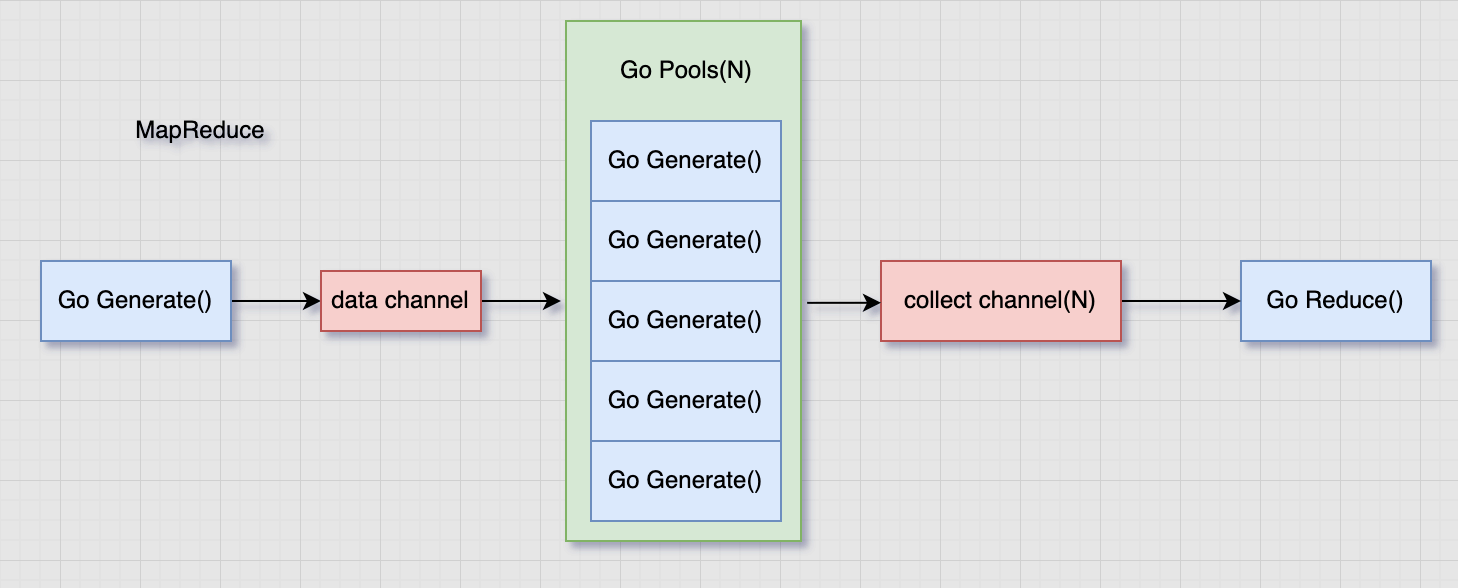
go-zero通过mapreduce来处理这种对输入数据进行处理最后输出清洗数据的问题。是一种经典的模式:生产者消费者模式 。将数据处理分为三个阶段:
数据生产 generate(查询,必选)
数据加工 mapper(加工,可选)
数据聚合 reducer(聚合,可选)
利用协程处理以及管道通信,实现数据的加速处理
对数据批处理,比如对一批用户id,效验每个用户的合法性并且效验过程中有一个出错就认为效验失败,返回的结果为效验合法的用户id
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 package mapreduceimport ( "errors" "log" "github.com/zeromicro/go-zero/core/mr" ) func Run (uids []int ) ([]int , error) r, err := mr.MapReduce(func (source chan <- interface {}) for _, uid := range uids { source <- uid } }, func (item interface {}, writer mr.Writer, cancel func (error) ) uid := item.(int ) ok, err := check(uid) if err != nil { cancel(err) } if ok { writer.Write(uid) } }, func (pipe <-chan interface {}, writer mr.Writer, cancel func (error) ) var uids []int for p := range pipe { uids = append (uids, p.(int )) } writer.Write(uids) }) if err != nil { log.Printf("check error: %v" , err) return nil , err } return r.([]int ), nil } func check (uid int ) (bool , error) if uid == 0 { return false , errors.New("uid wrong" ) } return true , nil }
其实是利用N个协程等待数据生产者的数据传输然后转交给聚合逻辑处理
某些功能的结果往往需要依赖多个服务,比如商品详情的结果往往会依赖用户服务、库存服务、订单服务等等,一般被依赖的服务都是以rpc的形式对外提供,为了降低依赖的耗时我们往往需要对依赖做并行处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 func productDetail (uid, pid int64 ) (*ProductDetail, error) var pd ProductDetail err := mr.Finish(func () (err error) pd.User, err = userRpc.User(uid) return }, func () (err error) pd.Store, err = storeRpc.Store(pid) return }, func () (err error) pd.Order, err = orderRpc.Order(pid) return }) if err != nil { log.Printf("product detail error: %v" , err) return nil , err } return &pd, nil }
源码目录:core/mr/mapreduce.go
其中利用到的对外函数有
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func MapReduce (generate GenerateFunc, mapper MapperFunc, reducer ReducerFunc, opts ...Option) (interface {}, error) func MapReduceChan (source <-chan interface {}, mapper MapperFunc, reducer ReducerFunc, opts ...Option) (interface {}, error) panicChan := &onceChan{channel: make (chan interface {})} return mapReduceWithPanicChan(source, panicChan, mapper, reducer, opts...) } func ForEach (generate GenerateFunc, mapper ForEachFunc, opts ...Option) func FinishVoid (fns ...func () ) func Finish (fns ...func () error ) error func WithWorkers (workers int ) Option
首先定义 buildSource使用协程进行数据生产
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func buildSource (generate GenerateFunc, panicChan *onceChan) chan interface source := make (chan interface {}) go func () defer func () if r := recover (); r != nil { panicChan.write(r) } close (source) }() generate(source) }() return source }
其中的 onceChan则是一个非阻塞会缓冲的channel,当channel中还有数据没有处理完,则直接返回
1 2 3 4 5 6 7 8 9 10 11 12 type onceChan struct { channel chan interface {} wrote int32 } func (oc *onceChan) write (val interface {}) if atomic.AddInt32(&oc.wrote, 1 ) > 1 { return } oc.channel <- val }
接着利用mapReduceWithPanicChan进行数据处理mapper和数据聚合reducer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 func MapReduce (generate GenerateFunc, mapper MapperFunc, reducer ReducerFunc, opts ...Option) (interface {}, error) panicChan := &onceChan{channel: make (chan interface {})} source := buildSource(generate, panicChan) return mapReduceWithPanicChan(source, panicChan, mapper, reducer, opts...) } func mapReduceWithPanicChan (source <-chan interface {}, panicChan *onceChan, mapper MapperFunc, reducer ReducerFunc, opts ...Option) (interface {}, error) options := buildOptions(opts...) output := make (chan interface {}) collector := make (chan interface {}, options.workers) done := make (chan lang.PlaceholderType) writer := newGuardedWriter(options.ctx, output, done) var closeOnce sync.Once go func () reducer(collector, writer, cancel) }() go executeMappers(mapperContext{ ctx: options.ctx, mapper: func (item interface {}, w Writer) mapper(item, w, cancel) }, source: source, panicChan: panicChan, collector: collector, doneChan: done, workers: options.workers, }) select { case <-options.ctx.Done(): cancel(context.DeadlineExceeded) return nil , context.DeadlineExceeded case v := <-panicChan.channel: panic (v) case v, ok := <-output: if err := retErr.Load(); err != nil { return nil , err } else if ok { return v, nil } else { return nil , ErrReduceNoOutput } } }
其中数据处理阶段又定义了一个协程进行处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 func executeMappers (mCtx mapperContext) var wg sync.WaitGroup defer func () wg.Wait() close (mCtx.collector) drain(mCtx.source) }() var failed int32 pool := make (chan lang.PlaceholderType, mCtx.workers) writer := newGuardedWriter(mCtx.ctx, mCtx.collector, mCtx.doneChan) for atomic.LoadInt32(&failed) == 0 { select { case <-mCtx.ctx.Done(): return case <-mCtx.doneChan: return case pool <- lang.Placeholder: item, ok := <-mCtx.source if !ok { <-pool return } wg.Add(1 ) go func () defer func () if r := recover (); r != nil { atomic.AddInt32(&failed, 1 ) mCtx.panicChan.write(r) } wg.Done() <-pool }() mCtx.mapper(item, writer) }() } } }
最后来看一下是数据处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 type guardedWriter struct { ctx context.Context channel chan <- interface {} done <-chan lang.PlaceholderType } func newGuardedWriter (ctx context.Context, channel chan <- interface {}, done <-chan lang.PlaceholderType) guardedWriter return guardedWriter{ ctx: ctx, channel: channel, done: done, } }
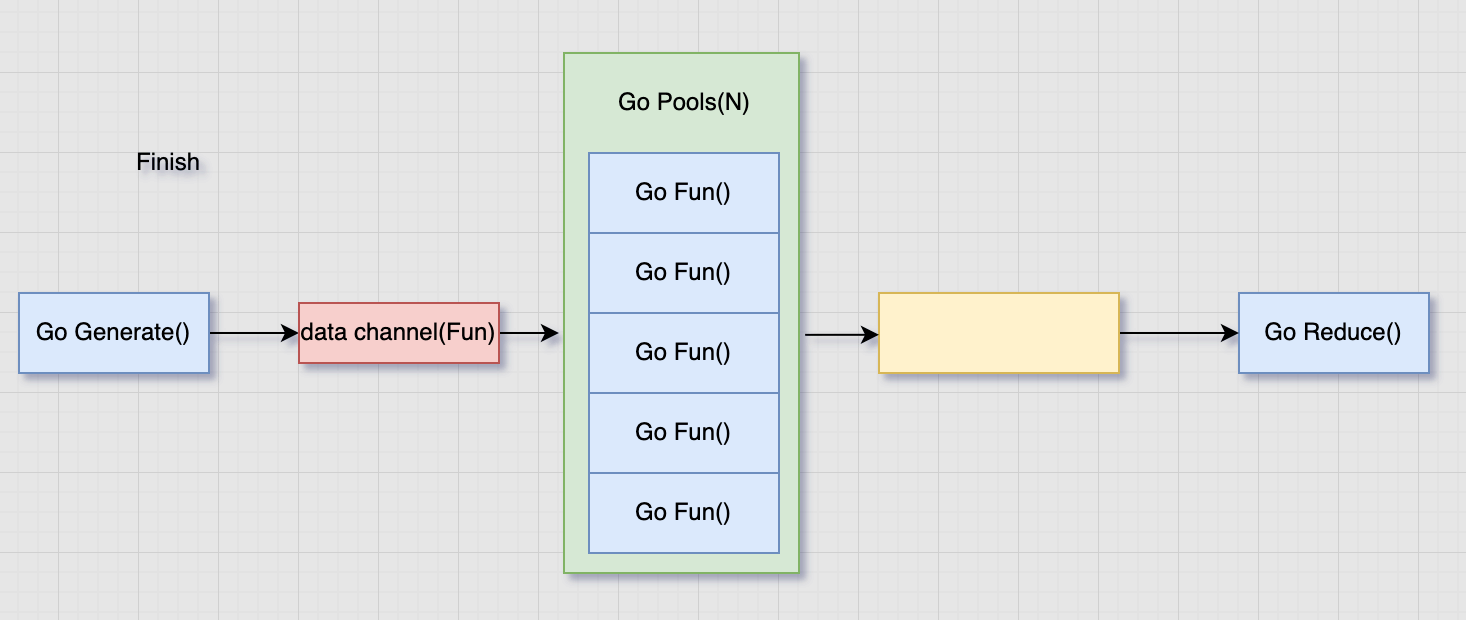
Finish逻辑只进行并发处理,其实内部是将执行函数做为数据生产的生产的数据,然后又数据处理逻辑进行处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 func Finish (fns ...func () error ) error if len (fns) == 0 { return nil } return MapReduceVoid(func (source chan <- interface {}) for _, fn := range fns { source <- fn } }, func (item interface {}, writer Writer, cancel func (error) ) fn := item.(func () error ) if err := fn(); err != nil { cancel(err) } }, func (pipe <-chan interface {}, cancel func (error) ) }, WithWorkers(len (fns))) } func MapReduceVoid (generate GenerateFunc, mapper MapperFunc, reducer VoidReducerFunc, opts ...Option) error _, err := MapReduce(generate, mapper, func (input <-chan interface {}, writer Writer, cancel func (error) ) reducer(input, cancel) }, opts...) if errors.Is(err, ErrReduceNoOutput) { return nil } return err }
适用于并发无顺序依赖的并发调用,如果是多个调用具有前后依赖关系,依然需要有先后调用顺序(废话)
也不存在回滚的操作,内部只是将不在等待处理结果直接退出 select
https://talkgo.org/t/topic/1452 https://zh.wikipedia.org/wiki/MapReduce