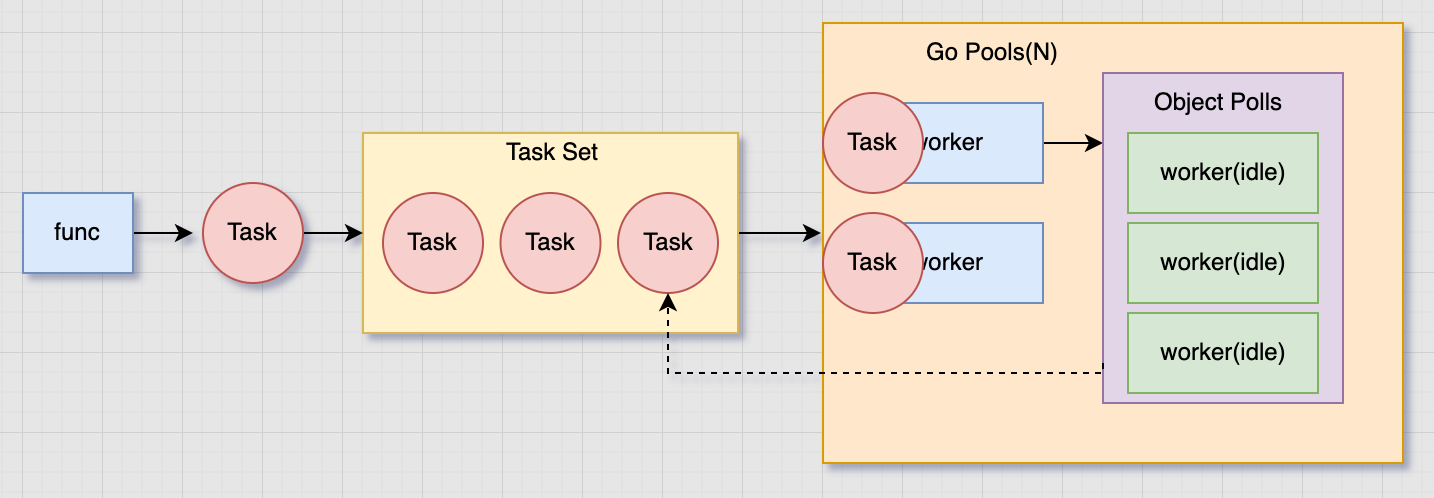
需要协程池吗?
虽然协程非常轻量级的,一般用不上协程池。协程池的作用 无休止地创建大量goroutine,势必会因为对大量go 程的创建、调度和销毁带来性能损耗。 为了解决这个问题,可以引入协程池
协程池需要什么?
协程如何重用、任务如何执行
协程池支持自定义协程池大小
如果当前任务数量超过协程池大小,那么当前任务需要等待,等待时间支持超时退出
协程支持自定义退出
异常捕获,防止因为单个协程的异常处理导致整个协程池无法使用
协程池大致的逻辑如下图所示:
这是一个网上能搜到的 “100行实现一个协程池”,
第一步 :定义一个任务
1 2 3 4 type Task struct { Handler func (v ...interface {}) Params []interface {} }
其实是将需要执行的协程方法,使用结构体封装起来
第二步 :定义一个协程池
1 2 3 4 5 6 7 8 9 10 11 12 13 type Pool struct { capacity uint64 runningWorkers uint64 status int64 chTask chan *Task PanicHandler func (interface {}) //panic 处理函数 sync.Mutex } const ( RUNNING = 1 STOPED = 0 )
第三步 :利用协程池启动一个协程执行任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 func (p *Pool) run () p.incRunning() go func () defer func () p.decRunning() if r := recover (); r != nil { if p.PanicHandler != nil { p.PanicHandler(r) } else { log.Printf("Worker panic: %s\n" , r) } } p.checkWorker() }() for { select { case task, ok := <-p.chTask: if !ok { return } task.Handler(task.Params...) } } }() } func (p *Pool) checkWorker () p.Lock() defer p.Unlock() if p.runningWorkers == 0 && len (p.chTask) > 0 { p.run() } }
协程池的协程不是常驻协程吗,为什么会出现协程数量为0,但是任务大于0的情况呢?
答:工作协程可能因为 panic 都退出了,那么这个时候就需要有一个重新拉起协程去执行任务
第四步 :生产任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 func (p *Pool) Put (task *Task) error p.Lock() defer p.Unlock() if p.status == STOPED { return ErrPoolAlreadyClosed } if p.GetRunningWorkers() < p.GetCap() { p.run() } if p.status == RUNNING { p.chTask <- task } return nil }
为什么在存放任务的时候,会多一个协程池的判断呢?
答:可能会出现协程池结束关闭的情况,如果这个时候又有新的任务,那就又会创建新的协程去执行
最后 :关闭协程池
1 2 3 4 5 6 7 8 9 10 11 12 13 func (p *Pool) Close () if !p.setStatus(STOPED) { return } for len (p.chTask) > 0 { time.Sleep(1e6 ) } close (p.chTask) }
总结 :
这里添加了协程池的状态,防止退出时候的任务增加
为什么在退出的时候,如果任务大于0,那么需要 sleep 一下?
异常捕获之后再次检查是否有协程在执行任务,没有则添加一个协程
使用无缓冲channel进行任务执行,可能会出现添加任务阻塞的情况
任务是否可以添加一个运行超时时间,防止单个任务死锁?
字节跳动开源的协程池,仓库地址:https://github.com/bytedance/gopkg/tree/develop/util/gopool
使用 生产者-消费者模式 设计协程池
第一步 :协程池 具有的功能
1 2 3 4 5 6 7 8 type Pool interface { Name() string SetCap(cap int32 ) Go(f func () ) //使用协程执行 f CtxGo(ctx context.Context, f func () ) //使用协程执行f 并支持参数 ctx SetPanicHandler(f func (context.Context, interface {}) ) //设置协程处理函数 WorkerCount() int32 }
第二步 :协程池的结构
1 2 3 4 5 6 7 8 9 10 11 type pool struct { name string cap int32 config *Config taskHead *task taskTail *task taskLock sync.Mutex taskCount int32 workerCount int32 panicHandler func (context.Context, interface {}) //Panic 处理逻辑 }
第三步 :看看 任务 task 的定义
1 2 3 4 5 6 7 8 9 10 11 12 type task struct { ctx context.Context f func () //执行函数 next *task } type taskList struct { sync.Mutex taskHead *task taskTail *task }
第四步 :查看协程池是怎么运行的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 var taskPool sync.Pool func (p *pool) CtxGo (ctx context.Context, f func () ) t := taskPool.Get().(*task) t.ctx = ctx t.f = f p.taskLock.Lock() if p.taskHead == nil { p.taskHead = t p.taskTail = t } else { p.taskTail.next = t p.taskTail = t } p.taskLock.Unlock() atomic.AddInt32(&p.taskCount, 1 ) if (atomic.LoadInt32(&p.taskCount) >= p.config.ScaleThreshold && p.WorkerCount() < atomic.LoadInt32(&p.cap )) || p.WorkerCount() == 0 { p.incWorkerCount() w := workerPool.Get().(*worker) w.pool = p w.run() } }
这里额外定义了一个 workPool,其实是消费者池
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 var workerPool sync.Pooltype worker struct { pool *pool } func (w *worker) run () go func () for { var t *task w.pool.taskLock.Lock() if w.pool.taskHead != nil { t = w.pool.taskHead w.pool.taskHead = w.pool.taskHead.next atomic.AddInt32(&w.pool.taskCount, -1 ) } if t == nil { w.close () w.pool.taskLock.Unlock() w.Recycle() return } w.pool.taskLock.Unlock() func () defer func () if r := recover (); r != nil { if w.pool.panicHandler != nil { w.pool.panicHandler(t.ctx, r) } else { msg := fmt.Sprintf("GOPOOL: panic in pool: %s: %v: %s" , w.pool.name, r, debug.Stack()) logger.CtxErrorf(t.ctx, msg) } } }() t.f() }() t.Recycle() } }() } func (w *worker) close () w.pool.decWorkerCount() } func (w *worker) zero () w.pool = nil } func (w *worker) Recycle () w.zero() workerPool.Put(w) }
最后,它还定义了一个 poolMap 用于根据名称注册与使用 多个协程池
注意 :
使用双向链表存储任务,表示它理论上支持无限个任务。后面的任务可能存在长时间等待的情况
使用任务上限的好处是,不是每来一个任务都开启一个协程,而是任务超过一定数量而又空闲的协程才开启新的协程去执行
go-zero是如何实现协程池的,代码路径:core/threading
第一步 ,定义了recover逻辑,用于 panic 之后的清理操作
1 2 3 4 5 6 7 8 9 10 func Recover (cleanups ...func () ) for _, cleanup := range cleanups { cleanup() } if p := recover (); p != nil { } }
第二步 ,定义了一个安全运行goroutine的方案 GoSafe,包含处理panic逻辑
1 2 3 4 5 6 7 8 9 func GoSafe (fn func () ) go RunSafe(fn) } func RunSafe (fn func () ) defer rescue.Recover() fn() }
TaskRunner: 使用 limitChan 协程池 执行协程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 type TaskRunner struct { limitChan chan lang.PlaceholderType } func NewTaskRunner (concurrency int ) *TaskRunner return &TaskRunner{ limitChan: make (chan lang.PlaceholderType, concurrency), } } func (rp *TaskRunner) Schedule (task func () ) rp.limitChan <- lang.Placeholder go func () defer rescue.Recover(func () <-rp.limitChan }) task() }() }
注意 :当limitChan满那么任务执行会出现超时,缺乏超时逻辑
WorkerGroup:使用 wokers 并发执行任务 job
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 type WorkerGroup struct { job func () workers int } func NewWorkerGroup (job func () , workers int ) WorkerGroup return WorkerGroup{ job: job, workers: workers, } } func (wg WorkerGroup) Start () group := NewRoutineGroup() for i := 0 ; i < wg.workers; i++ { group.RunSafe(wg.job) } group.Wait() }
RoutineGroup: 多协程等待
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 type RoutineGroup struct { waitGroup sync.WaitGroup } func NewRoutineGroup () *RoutineGroup return new (RoutineGroup) } func (g *RoutineGroup) Run (fn func () ) g.waitGroup.Add(1 ) go func () defer g.waitGroup.Done() fn() }() } func (g *RoutineGroup) RunSafe (fn func () ) g.waitGroup.Add(1 ) GoSafe(func () defer g.waitGroup.Done() fn() }) } func (g *RoutineGroup) Wait () g.waitGroup.Wait() }
所以 go-zero的threading 并不是真正的协程池,仅仅是提供多种并发执行 goroutine的方法
所以从目前来看,实现一个协程池都有哪些值得学习的地方呢?
将需要使用临时协程执行的函数已任务的形式 任务 -- 协程池(Pool) -- 工人执行
协程池是有容量限制的,有了容量就有正在运行的协程数
协程池有状态防止在退出的时候仍然进行任务构建与执行
协程池有异常捕获机制,保证单个异常不会影响整个协程池
任务已任务合集的形式存在,让消费者并发消费
有了异常捕获与任务合集,为了防止工人都发生异常,而还有任务没有执行,则需要有工人唤起机制
可以使用本地缓存池进行工人的重复利用
任务合集缓隧道还是双链表、每个任务都构建一个协程还是单个任务多任务执行的选择
下一节,将学习另外一个协程池 ants 的实现方式
https://go-zero.dev/cn/docs/goctl/installation/