问题背景
调用链路错综复杂,做为服务的提供者需要有一种保护自己的机制,防止调用方无脑调用压垮自己,保证自身服务的高可用。自适应降载能根据服务自身的系统负载动态判断是否需要降载,它的目标:
- 保证系统不被拖垮
- 在系统稳定的前提下,保持系统的吞吐量
问题:服务怎么知道自己需要降载?
通过CPU负载与并发数判断往往存在较大波动,这种被称为毛刺的现象可能导致系统一致频繁的自动进行降载操作。所以如果能通过统计最近一段时间内的指标均值使均值更加平滑
实现原理
统计学上有一种算法:滑动平均(exponential moving average),用来估算变量的局部均值,使得变量的更新与历史一段时间的历史取值有关,无需记录所有的历史局部变量就可以实现平均值估算
变量 V 在 t 时刻记为 Vt,θt 为变量 V 在 t 时刻的取值,即在不使用滑动平均模型时 Vt=θt,在使用滑动平均模型后,Vt 的更新公式如下:
Vt=β⋅Vt−1+(1−β)⋅θt
- β = 0 时 Vt = θt
- β = 0.9 时,大致相当于过去 10 个 θt 值的平均
- β = 0.99 时,大致相当于过去 100 个 θt 值的平均
而统计最近一段时间内的数据则可以使用 滑动窗口算法,接下来看看如何进行自适应降载判断
技术内幕
来看看 go-zero 的自适应降载的实现
代码:core/load/adaptiveshedder.go
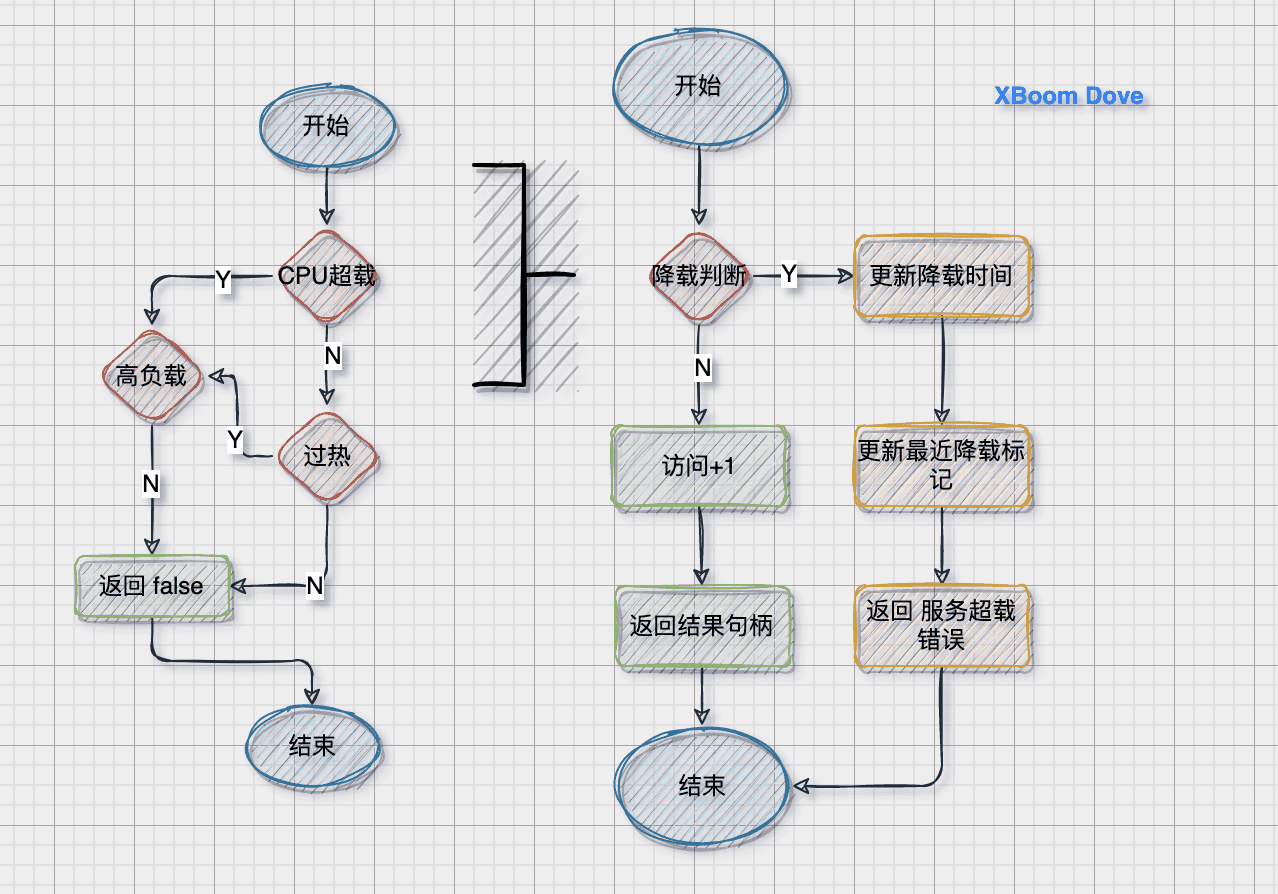
使用案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| func UnarySheddingInterceptor(shedder load.Shedder, metrics *stat.Metrics) grpc.UnaryServerInterceptor {
ensureSheddingStat()
return func(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo,
handler grpc.UnaryHandler) (val interface{}, err error) {
sheddingStat.IncrementTotal()
var promise load.Promise
promise, err = shedder.Allow()
if err != nil {
metrics.AddDrop()
sheddingStat.IncrementDrop()
return
}
defer func() {
if err == context.DeadlineExceeded {
promise.Fail()
} else {
sheddingStat.IncrementPass()
promise.Pass()
}
}()
return handler(ctx, req)
}
}
|
仅需要调用 Allow 接口进行降载逻辑初始化
- 如果降载
shedder.Allow(),那么直接记录信息并返回
- 否则执行业务逻辑
- 成功则执行
promise.Pass
- 失败则执行
promise.Fail,业务调用错误这种算执行成功,这里使用业务超时(DeadlineExceeded)表示执行失败需要降载。
这里的promise变量就是上图中的返回结果句柄,用于将业务逻辑结果更新到降载器中
接口定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| const (
defaultBuckets = 50
defaultWindow = time.Second * 5
defaultCpuThreshold = 900
defaultMinRt = float64(time.Second / time.Millisecond)
flyingBeta = 0.9
coolOffDuration = time.Second
)
type (
Promise interface {
Pass()
Fail()
}
Shedder interface {
Allow() (Promise, error)
}
ShedderOption func(opts *shedderOptions)
shedderOptions struct {
window time.Duration
buckets int
cpuThreshold int64
}
adaptiveShedder struct {
cpuThreshold int64
windows int64
flying int64
avgFlying float64
avgFlyingLock syncx.SpinLock
dropTime *syncx.AtomicDuration
droppedRecently *syncx.AtomicBool
passCounter *collection.RollingWindow
rtCounter *collection.RollingWindow
}
)
|
初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func NewAdaptiveShedder(opts ...ShedderOption) Shedder {
if !enabled.True() {
return newNopShedder()
}
bucketDuration := options.window / time.Duration(options.buckets)
return &adaptiveShedder{
cpuThreshold: options.cpuThreshold,
windows: int64(time.Second / bucketDuration),
dropTime: syncx.NewAtomicDuration(),
droppedRecently: syncx.NewAtomicBool(),
passCounter: collection.NewRollingWindow(options.buckets, bucketDuration,
collection.IgnoreCurrentBucket()),
rtCounter: collection.NewRollingWindow(options.buckets, bucketDuration,
collection.IgnoreCurrentBucket()),
}
}
|
逻辑判断
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
func (as *adaptiveShedder) Allow() (Promise, error) {
if as.shouldDrop() {
as.dropTime.Set(timex.Now())
as.droppedRecently.Set(true)
return nil, ErrServiceOverloaded
}
as.addFlying(1)
return &promise{
start: timex.Now(),
shedder: as,
}, nil
}
|
结果句柄操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| type promise struct {
start time.Duration
shedder *adaptiveShedder
}
func (p *promise) Fail() {
p.shedder.addFlying(-1)
}
func (p *promise) Pass() {
rt := float64(timex.Since(p.start)) / float64(time.Millisecond)
p.shedder.addFlying(-1)
p.shedder.rtCounter.Add(math.Ceil(rt))
p.shedder.passCounter.Add(1)
}
|
注意
- 其中的
p.shedder.addFlying(-1) 也就是说 flying 变量用于更新调度请求数量的
- 失败并不会记录到调度统计中,因为计算平均请求不需要失败
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| func (as *adaptiveShedder) addFlying(delta int64) {
flying := atomic.AddInt64(&as.flying, delta)
if delta < 0 {
as.avgFlyingLock.Lock()
as.avgFlying = as.avgFlying*flyingBeta + float64(flying)*(1-flyingBeta)
as.avgFlyingLock.Unlock()
}
}
|
CPU超过限制
这里的CPU也是经过定时统计得出的最近一段时间CPU负载,防止毛刺
1
2
3
| systemOverloadChecker = func(cpuThreshold int64) bool {
return stat.CpuUsage() >= cpuThreshold
}
|
过载中判断
如果是正在过载中则,超过一段时间冷静期就恢复正常
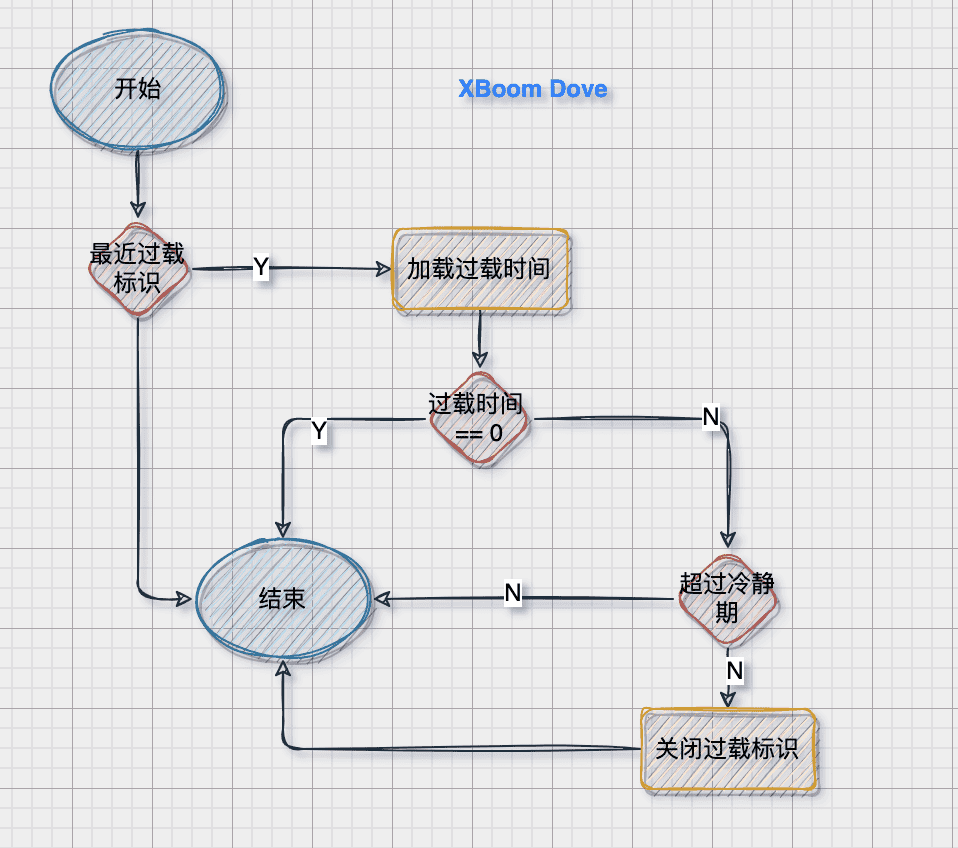
过载标识/时间 是当初过载时候设置的 dropTime 与droppedRecently
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func (as *adaptiveShedder) stillHot() bool {
if !as.droppedRecently.True() {
return false
}
dropTime := as.dropTime.Load()
if dropTime == 0 {
return false
}
hot := timex.Since(dropTime) < coolOffDuration
if !hot {
as.droppedRecently.Set(false)
}
return hot
}
|
过载判断
过载判断 的逻辑是
1
2
|
avgFlying > maxFlight && flying > maxFlight
|
这个 最大并发数 又是怎样计算的呢?
当前系统的最大并发数 = 窗口单位时间内的最大通过数量 * 窗口单位时间内的最小响应时间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| func (as *adaptiveShedder) maxFlight() int64 {
return int64(math.Max(1, float64(as.maxPass()*as.windows)*(as.minRt()/1e3)))
}
func (as *adaptiveShedder) maxPass() int64 {
var result float64 = 1
as.passCounter.Reduce(func(b *collection.Bucket) {
if b.Sum > result {
result = b.Sum
}
})
return int64(result)
}
func (as *adaptiveShedder) minRt() float64 {
result := defaultMinRt
as.rtCounter.Reduce(func(b *collection.Bucket) {
if b.Count <= 0 {
return
}
avg := math.Round(b.Sum / float64(b.Count))
if avg < result {
result = avg
}
})
return result
}
|
总结
- 自适应降载逻辑处理 当请求突然增大的时候,虽然没有达到服务能够承受的极限,也有可能出现降载。因为平均请求数量以及最大请求数量 都超过了最近一段时间能承载的最大水平
- 按照第一条逻辑,如果服务刚启动那会请求确实比较多,是不是就会出现降载了。不会,这里在计算 最大并发数的时候,给定了一个最小最大并发数
1 * defaultMinRt / milliseconds_per_second 。也就是并发数低于 1000的时候也不会触发降载
参考文档
- https://talkgo.org/t/topic/3058
- https://www.cnblogs.com/wuliytTaotao/p/9479958.html