生产者
如下图是生产者客户端的整体架构
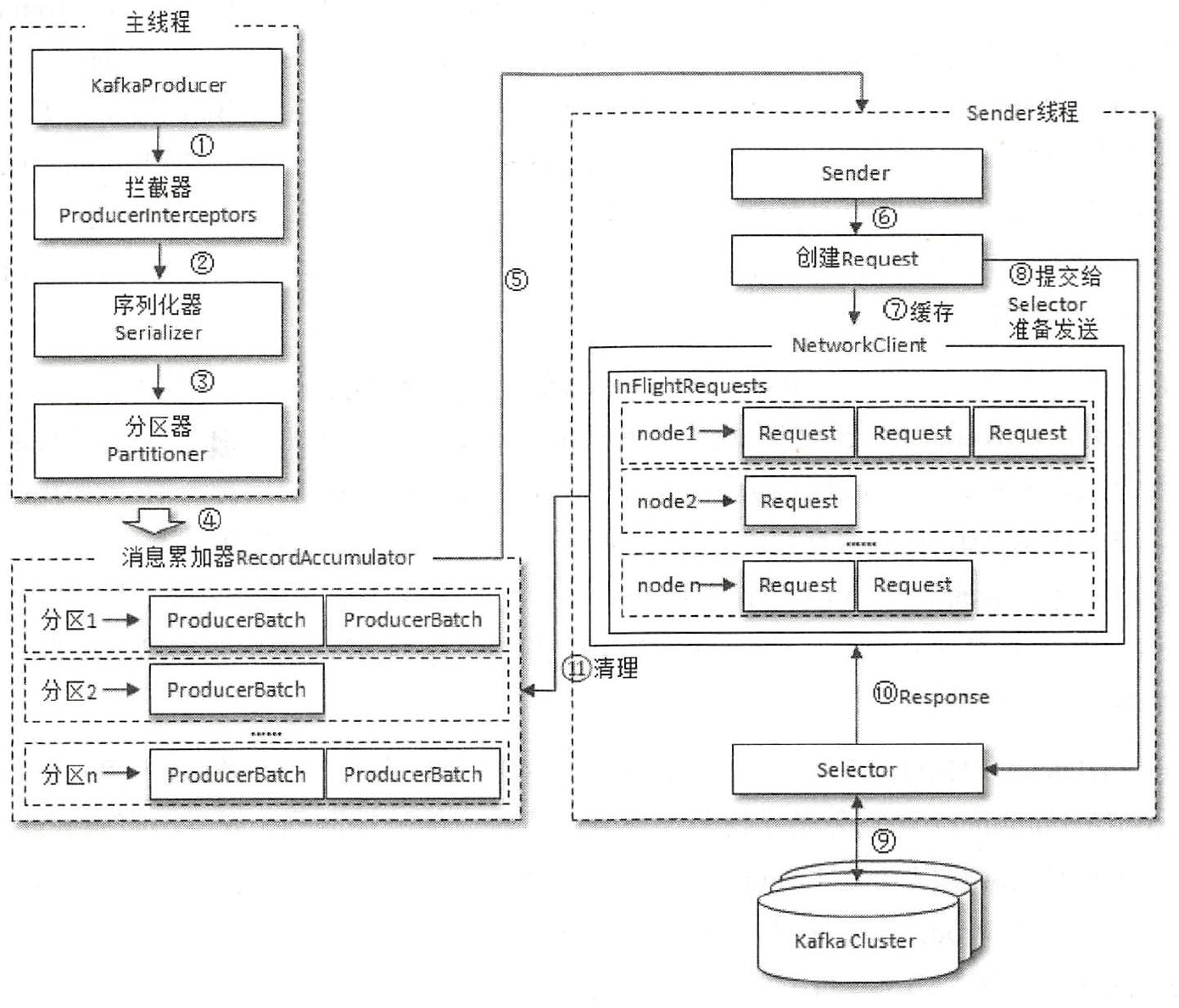
整个生产者客户端由两个线程协调运行,这两个线程分别为
-
主线程:由 Producer 创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器( RecordAccumulator ,也称为消息收集器〉中
-
Sender 线程(发送线程):负责从RecordAccumulator 中获取消息并将其发送到Kafka 中
RecordAccumulator 主要用来缓存消息以便批量发送,进而减少网络传输的资源消耗。RecordAccumulator 缓存的大小可通过客户端参数 buffer.memory 配置,默认32MB。
当生产者发送消息的速度超过发送到服务器的速度,则会导致生产者空间不足,这个时候KafkaProducer 的send()方法调用要么被阻塞,要么抛出异常,这个取决于参数 max.block.ms 的配置,此参数的默认值60 秒
重要的参数
-
acks(字符串类型):用来指定分区中必须要有多少个副本收到这条消息,之后生产者才会认为这条消息是成功写入的
-
acks = 1(默认):生产者发送消息之后,只要分区的leader 副本成功写入消息,那么它就会收到来自服务端的成功响应。
如果消息写入leader 副本并返回成功响应给生产者,且在被其他fo llower 副本拉取之前leader 副本崩溃,那么此时消息还是会丢失,因为新选举的leader 副本中并没有这条对应的消息。
-
Acks = 0:生产者发送消息之后不需要等待任何服务端的响应
-
Acks = -1:生产者在消息发送之后,需要等待ISR 中的所有副本都成功写入消息之后才能够收到来自服务端的成功响应
-
-
max.request.size:限制生产者客户端能发送的消息的最大值,默认值为1048576B ,即1MB
-
retries 和retry. backoff.ms:retries 参数用来配置生产者重试的次数,默认值为0,即在发生异常的时候不进行任何重试动作,retry. backoff.ms 则用来设置两次重试之间的间隔
-
compression.type:压缩方式
-
connections.max.idle.ms:指定在多久之后关闭闲置的连接,默认值是540000 ( ms ) ,即9 分钟
-
linger.ms:指定生产者发送ProducerBatch 之前等待更多消息( ProducerRecord )加入Producer Batch 的时间,默认值为0,生产者客户端会在ProducerBatch 被填满或等待时间超过
linger.ms值时发迭出去 -
recvive.buffer.bytes:设置Socket接收消息的缓冲区(SO_RECBUF)的大小,默认值32KB
-
send.buffer.bytes:设置Socket发送消息的缓冲区(SO_RECBUF)的大小,默认值128KB
-
request.time.ms:配置Producer等待请求响应的最长时间,默认值为3000(ms)
消费者
消费者(Consumer)负责订阅Kafka 中的主题(Topic),并从订阅的主题上拉取消息,每个消费者都有一个对应的消费组。当消息发布到主题后,只会被投递给订阅它的每个消费组中的一个消费者。
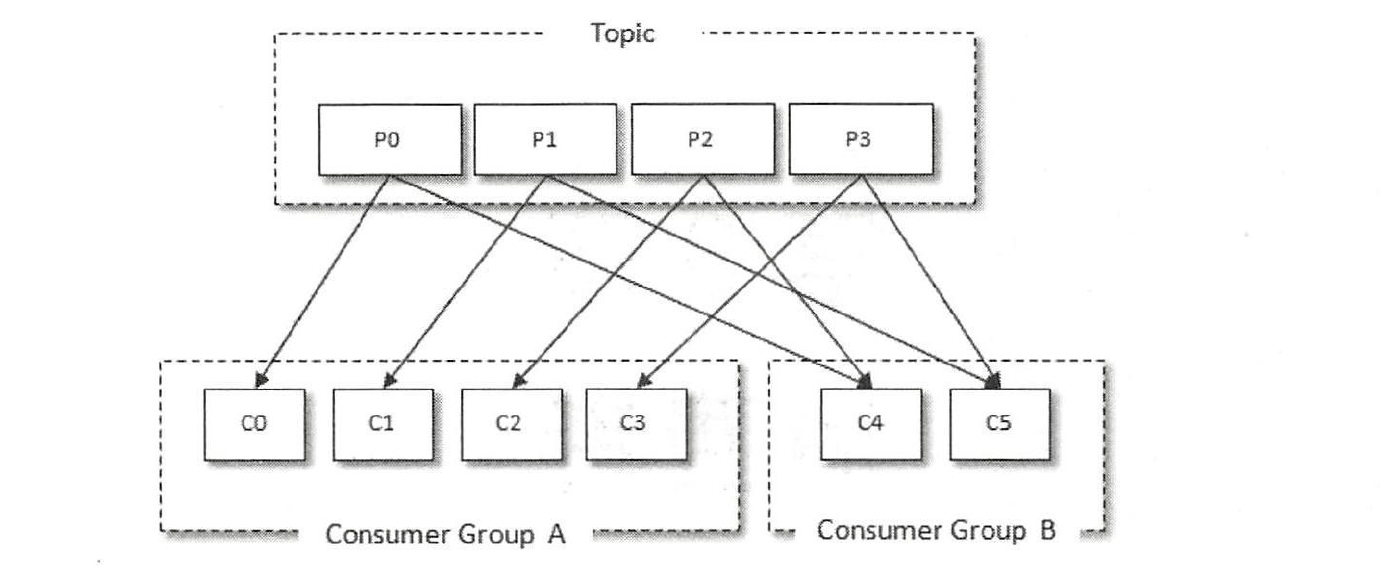
主题中共有4 个分区(Partition) : PO 、Pl 、P2 、P3 。有两个消费组A和B 都订阅了这个主题,消费组A 中有4 个消费者(CO 、Cl 、C2 和C3),消费组B 中有2个消费者(C4 和CS ) 。按照Kafka 默认的规则,最后的分配结果是消费组A 中的每一个消费者分配到l1个分区,消费组B 中的每一个消费者分配到2 个分区,两个消费组之间互不影响。每个消费者只能消费所分配到的分区中的消息。即每一个分区只能被一个消费组中的一个消费者所消费
假设目前某消费组内只有一个消费者C0 ,订阅了一个主题,这个主题包含7 个分区: PO 、Pl 、P2 、P3 、P4 、
PS 、P6 也就是说,这个消费者C0 订阅了7 个分区。消费组内又加入了一个新的消费者C1,按照既定的逻辑,需要将原来消费者C0 的部分分区分配给消费者C1消费, 彼此之间并无逻辑上的干扰

此时又加入了消费者C3,则按照上述规则继续分配。一昧地增加消费者并不会让消费能力一直得到提升,如果消费者过多,出现了消费者的个数大于分区个数的情况就会有消费者分配不到任何分区
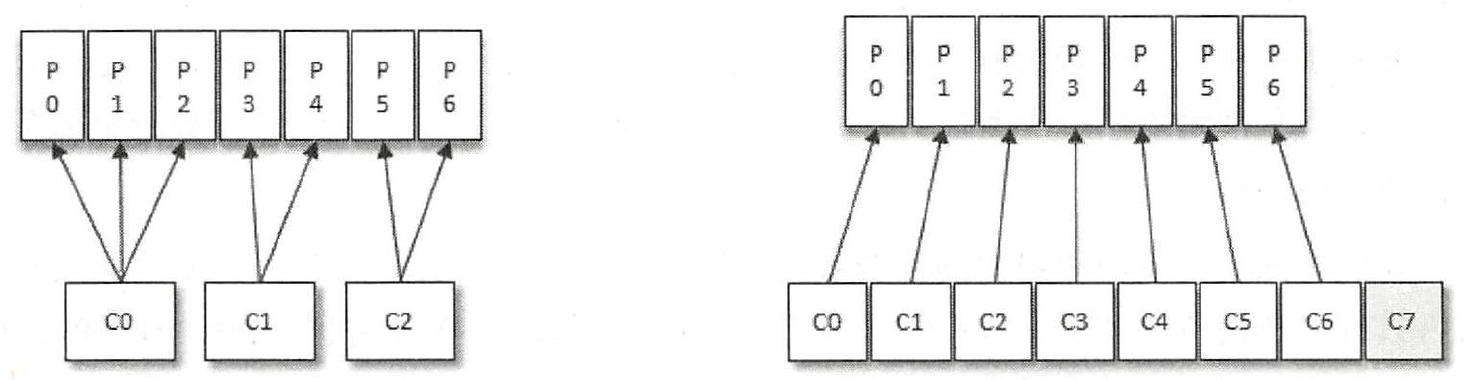
通过以上方式 Kafka支持两种投递方式:
-
如果所有的消费者都隶属于同一个消费组,那么所有的消息都会被均衡地投递给每一个消费者,即每条消息只会被一个消费者处理,这就相当于点对点模式的应用。
-
如果所有的消费者都隶属于不同的消费组,那么所有的消息都会被广播给所有的消费者,即每条消息会被所有的消费者处理,这就相当于发布/订阅模式的应用
如何实现多副本的发布订阅与广播
每一个消费者只隶属于一个消费组 !!!!!
一个消费者可以订阅一个或多个主题
每一个消费组都会有一个固定的名称,消费者在进行消费前需要指定其所属消费组的名称,这个可以通过消费者客户端参数group.id 来配置,默认值为空宇符串
消息消费
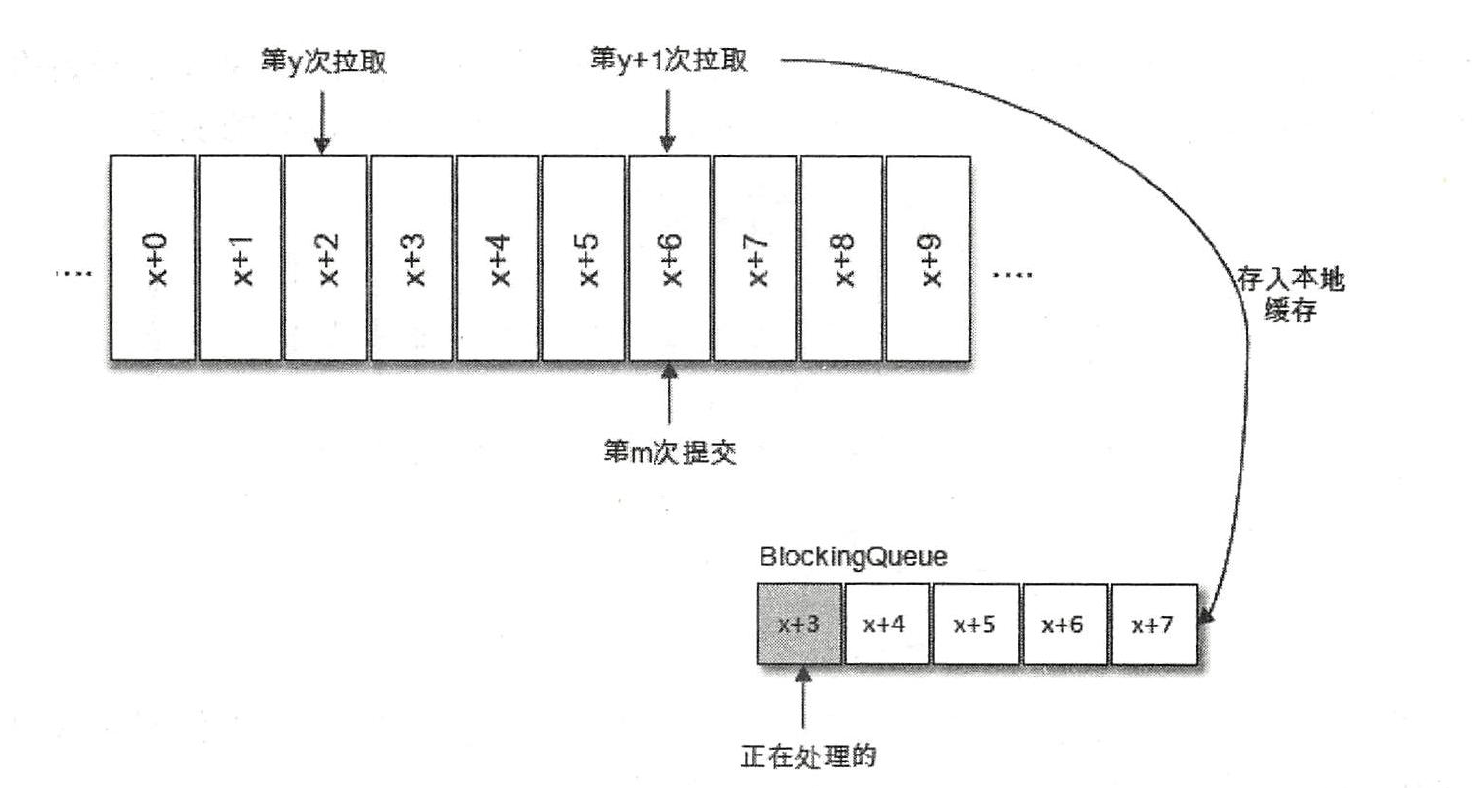
Kafka 中的消费是基于拉模式的,Kafka 中的消息消费是一个不断轮询的过程
在默认的方式下,消费者每隔5 秒会将拉取到的每个分区中最大的消息位移进行提交。自动位移提交的动作是在拉取的逻辑里完成的,在每次真正向服务端发起拉取请求之前会检查是否可以进行位移提交,如果可以,那么就会提交上一次轮询的位移。
在Kafka 消费的编程逻辑中位移提交是一大难点,自动提交消费位移的方式非常简便,它免去了复杂的位移提交逻辑,让编码更简洁。但随之而来的是重复消费和消息丢失的问题。假设刚刚提交完一次消费位移,然后拉取一批消息进行消费,在下一次自动提交消费位移之前,消费者崩溃了,那么又得从上一次位移提交的地方重新开始消费,这样便发生了重复消费的现象(对于再均衡的情况同样适用)。可以通过减小位移提交的时间间隔来减小重复消息的窗口大小,但这样并不能避免重复消费的发送,而且也会使位移提交更加频繁。
再平衡
再均衡是指分区的所属权从一个消费者转移到另一消费者的行为,在再均衡发生期间,消费组内的消费者是无法读取消息的,即一段时间消费组会变得不可用。
另外,当一个分区被重新分配给另一个消费者时, 消费者当前的状态也会丢失。比如消费者消费完某个分区中的一部分消息时还没有来得及提交消费位移就发生了再均衡操作, 之后这个分区又被分配给了消费组内的另一个消费者,原来被消费完的那部分消息又被重新消费一遍,也就是发生了重复消费。一般情况下,应尽量避免不必要的再均衡的发生
参考链接
- 《深入理解Kafka 核心设计与实践原理》