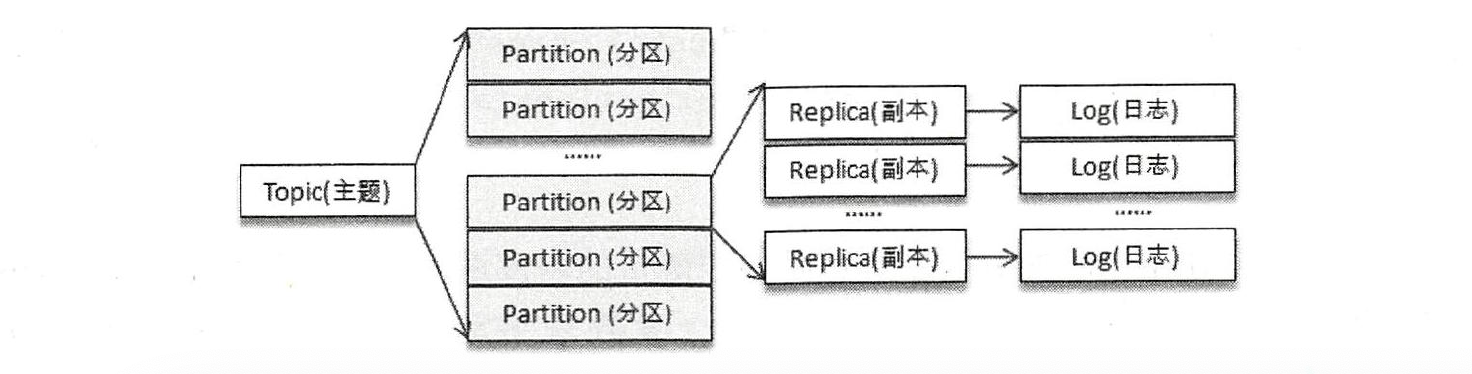
主题作为消息的归类,可以再细分为一个或多个分区,分区则可看作对消息的二次归类。
分区的划分不仅为Kafka 提供了可伸缩性、水平扩展的功能,还通过多副本机制提高数据可靠性
主题与分区都是逻辑上的概念,分区可以有一至多个副本,每个副本对应一个日志文件,每个日志文件对应一至多个日志分段(LogSegment),每个日志分段还可以细分为索引文件、日志存储文件和快照文件等
分区的管理
优先副本的选举
分区使用多副本机制来提升可靠性,但只有leader 副本对外提供读写服务,而follower 副本只负责在内部进行消息的同步
对同一个分区而言, 同一个broker 节点中不可能出现它的多个副本, 即Kafka 集群的一个broker 中最多只能有它的一个副本, 可以将leader 副本所在的broker 节点叫作分区的leader 节点,而follower副本所在的broker 节点叫作分区的follower 节点。
在创建主题的时候,该主题的分区及副本会尽可能均匀地分布到Kafka 集群的各个broker节点上,对应的leader 副本的分配也比较均匀。
将leader 副本所在的broker 节点叫作分区的leader 节点,而follower副本所在的broker 节点叫作分区的follower 节点。如果Kafka中leader副本过于集中在同一个节点上,集群会出现负载失衡的情况。
为此,Kafka 引入了优先副本(preferred replica) : 指在AR 集合列表中的第一个副本。也可以称之为preferred leader 。Kafka 要确保所有主题的优先副本在Kafka 集群中均匀分布,这样就保证了所有分区的leader 均衡分布。
所谓的优先副本的选举是指通过一定的方式促使优先副本选举为leader 副本,以此来促进集群的负载均衡, 这一行为也可以称为“分区平衡”
分区平衡并不意味着Kafka 集群的负载均衡!!!
因为还要考虑集群中的分区分配是否均衡。每个分区的leader 副本的负载也是各不相同的
Kafka 的控制器会启动一个定时任务,这个定时任务会轮询所有的broker节点,计算每个broker 节点的分区不平衡率( broker 中的不平衡率=非优先副本的leader 个数/分区总数)是否超过leader .mbalance.per.broker.percentage 参数配置的比值,默认值为10% ,如果超过设定的比值则会自动执行优先副本的选举动作以求分区平衡。执行周期由参数leader.Imbalance.check .interval . seconds 控制,默认值为3 00 秒
分区重分配
当集群中的一个节点突然若机下线时,
- 如果节点上的分区是单副本的,这些分区就变得不可用了,在节点恢复前,相应的数据也就处于丢失状态;
- 如果节点上的分区是多副本的,位于这个节点上的 leader 副本的角色会转交到集群的其他follower副本中。
总而言之,这个节点上的分区副本都已经处于功能失效的状态, Kafka 并不会将这些失效的分区副本自动地迁移到集群中剩余的可用broker 节点上,如果放任不管,则不仅会影响整个集群的均衡负载,还会影响整体服务的可用性和可靠性
分区重分配的基本原理是
- 第一步:添加新副本(增加副本因子)
- 第二步:新副本将从分区的 leader 副本那里复制所有的数据。根据分区的大小不同,复制过程可能需要花一些时间,因为数据是通过网络复制到新副本上的。
- 第三步:在复制完成之后,控制器将旧副本从副本清单里移除(恢复为原先的副本因子数)注意在重分配的过程中要确保有足够的空间。
分区重分配的量如果太大必然会严重影响整体的性能,对副本间的复制流量加以限制来保证重分配期间整体服务不会受太大的影响,复制限流有两种实现方式: kafka-config. sh 脚本和kafka-reassign-partitions .sh 脚本
参考链接
- 《深入理解Kafka 核心设计与实践原理》