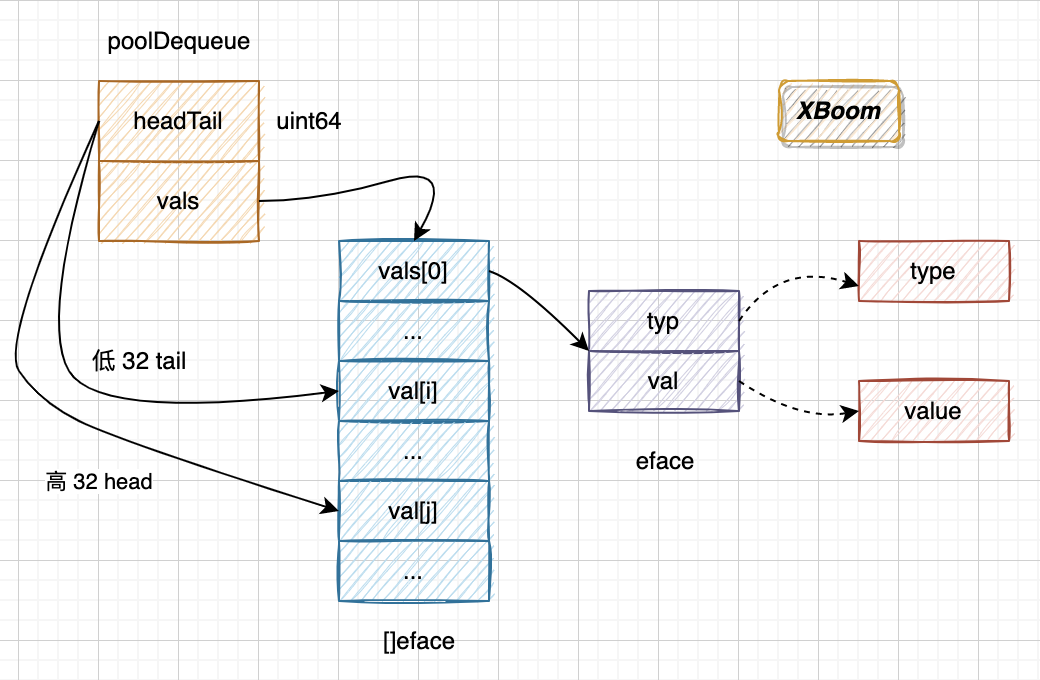
//5. 判断头部是否已经被释放 typ := atomic.LoadPointer(&slot.typ) if typ != nil { // Another goroutine is still cleaning up the tail, so // the queue is actually still full. returnfalse }
// The head slot is free, so we own it. //如果存放的是nil,那么使用 dequeueNil(nil) 表示存放的是一个nil类型 if val == nil { val = dequeueNil(nil) } *(*any)(unsafe.Pointer(slot)) = val
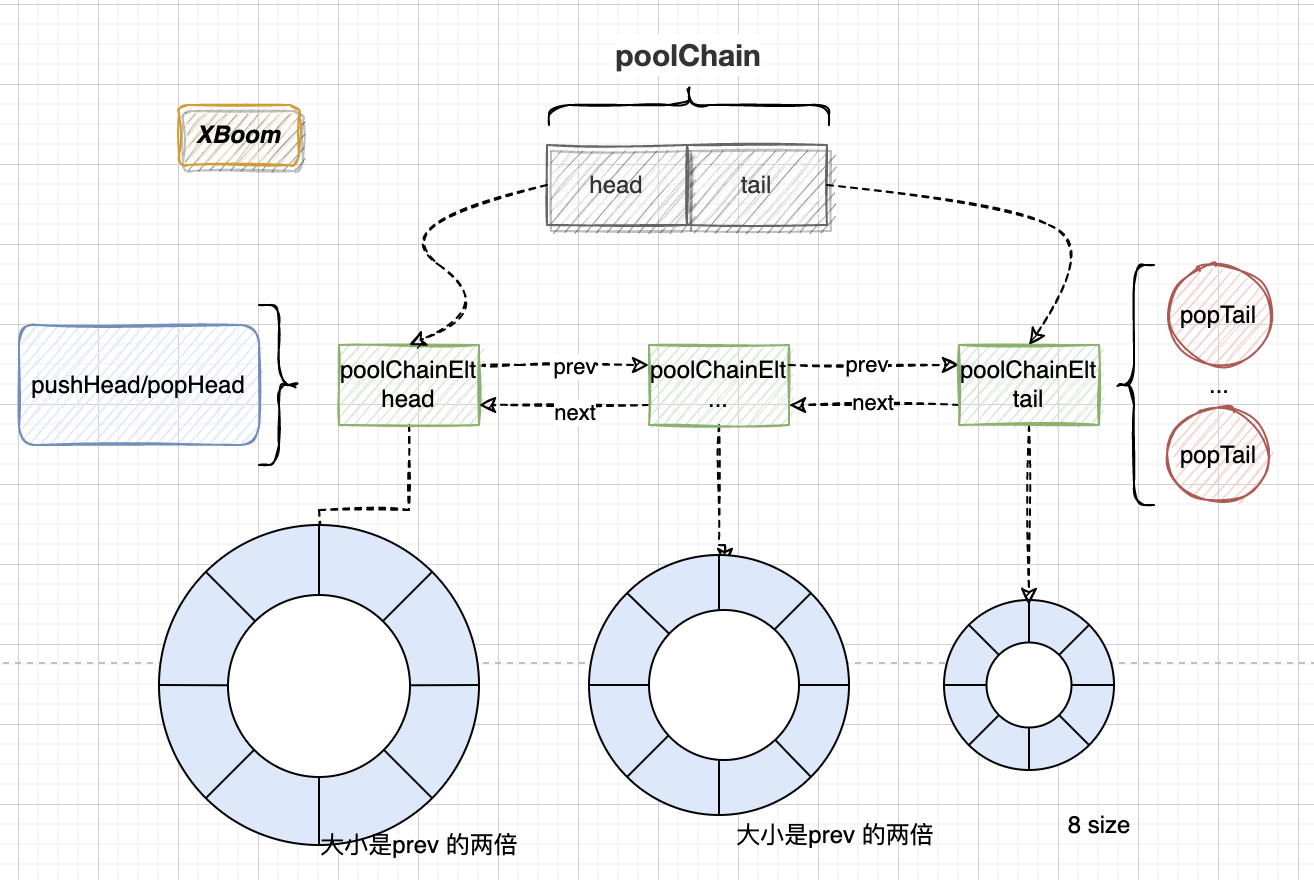
func(c *poolChain)popHead()(any, bool) { //获取头部节点 d := c.head for d != nil { //获取队列头部节点 if val, ok := d.popHead(); ok { return val, ok } // 到这里是没有获取到,然后指向前驱继续获取 d = loadPoolChainElt(&d.prev) } returnnil, false }
func(c *poolChain)popTail()(any, bool) { //1. 加载尾部队列节点,如果没有表示链表为空则返回 false d := loadPoolChainElt(&c.tail) if d == nil { returnnil, false }
for { // 记录尾部的后驱 d2 := loadPoolChainElt(&d.next)
// 弹出队列尾部值 if val, ok := d.popTail(); ok { return val, ok } // 如果 d 没有了,d2 也为空,说明没有值 if d2 == nil { returnnil, false }
// CAS 尝试获取 d if atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&c.tail)), unsafe.Pointer(d), unsafe.Pointer(d2)) { //如果获取到那么去掉前继 storePoolChainElt(&d2.prev, nil) } //更新尾部指针 d = d2 } }
总结:
无锁的原因是队列形式,单个生产者在头部操作,消费者从队尾消费
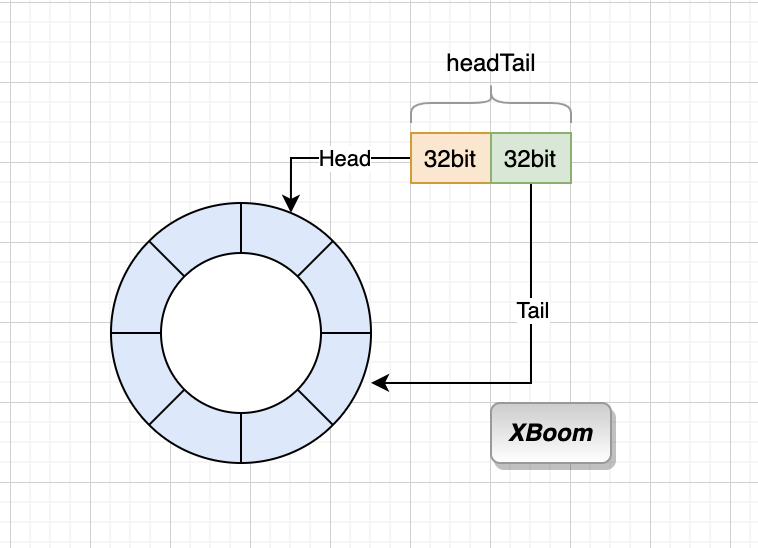
并不是固定大小,而是作为双向链表节点的队列最大长度是 1 << 32/ 4 ,并且用环形缓冲区 ring buffer 实现
Pool 底层 使用 数组 + 链表的形式的原因是由 Pool 的特性决定的,它需要频繁的内存分配,所以数组是一个好的选择。又为了解决扩容的问题,使用链表来连接数组