在阅读 Libevent 库的时候看到 TAILQ_ENTRY 的宏定义有点特别,这里记录一下,代码路径 libevent/compat/sys/queue.h
首先它实现的类似泛型的功能
1 2 3 4 5 6 #define TAILQ_ENTRY(type) \ struct { struct type *tqe_next ; struct type **tqe_prev ; } #endif
C11 中还能通过 _Generic关键字 实现泛型编程
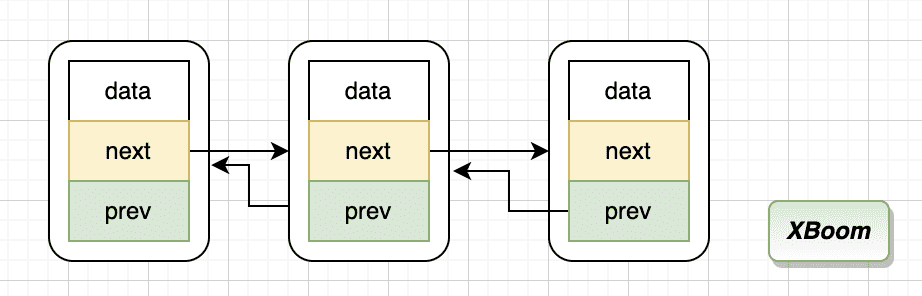
但是有一个奇怪的地方,tqe_prev 为什么是指针的指针,这里可能跟平时的好像不太一样?
平时定义的双向链表节点
1 2 3 4 5 6 struct Node { int data; struct Node * next ; struct Node * prev ; };
由它构建的双向链表结构
删除节点的操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void deleteNode (struct Node** head, int target) struct Node * current = *head ; while (current != NULL && current->data != target) { current = current->next; } if (current != NULL ) { if (current->prev != NULL ) { current->prev->next = current->next; } if (current->next != NULL ) { current->next->prev = current->prev; } free (current); } }
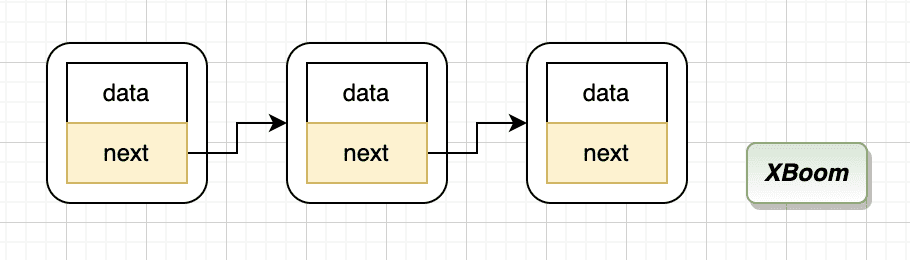
而平时定义的单向链表
1 2 3 4 struct node { int data; struct Node * next ; };
由它构建的单向链表
而单链表的删除操作是这样的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void deleteNode (struct Node** head, int target) struct Node * current = *head ; struct Node * prev = NULL ; while (current != NULL && current->data != target) { prev = current; current = current->next; } if (current != NULL ) { if (prev == NULL ) { *head = current->next; } else { prev->next = current->next; } free (current); } }
于是我又去看了 linux 内核中的链表结构,发现了它的使用
代码路径:libevent/compat/sys/queue.h
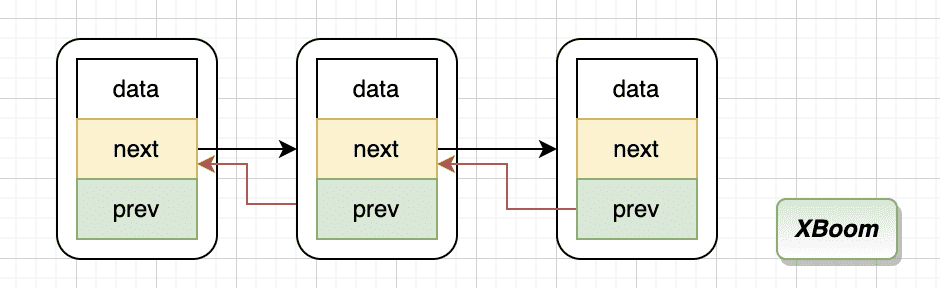
1 2 3 4 5 6 7 8 9 10 11 struct list_head { struct list_head *next , *prev ; }; struct hlist_head { struct hlist_node *first ; }; struct hlist_node { struct hlist_node *next , **pprev ; };
它在定义双向链表的同时,还定义了一个hlist_node用于 hash 表的桶链表,头节点使用 hlist_head表示。它的删除操作
1 2 3 4 5 6 7 8 9 static inline void __hlist_del(struct hlist_node *n){ struct hlist_node *next = n ->next ; struct hlist_node **pprev = n ->pprev ; WRITE_ONCE(*pprev, next); if (next) WRITE_ONCE(next->pprev, pprev); }
其中 WRITE_ONCE的宏是 Linux 内核中用于确保写入操作是原子的宏,也就是说 WRITE_ONCE(*pprev, next); 相当于原子操作 *pprev = next, 那么这个双向链表的结构是
跟自己定义的区别就是将 prev 的指针指向的是前一个节点的 next 指针,为什么这样做其实从删除操作可以看出来,不需要额外判断是否是头节点与尾节点
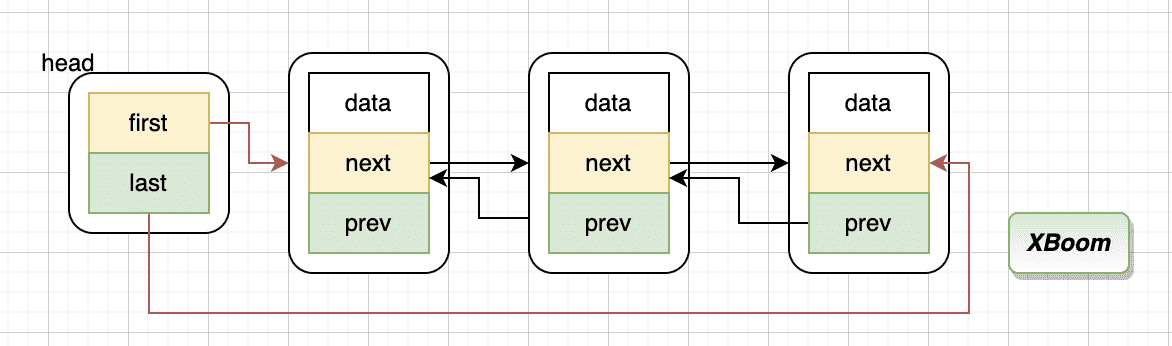
回到刚才的宏定义,有个双向链表节点,看它是如何完整的实现双向链表的
首先是初始化一个头部节点
1 2 3 4 5 6 struct event_list events ;TAILQ_INIT(&events); #define TAILQ_INIT(head) do { \ (head)->tqh_first = NULL ; \ (head)->tqh_last = &(head)->tqh_first; \ } while (0 )
也就是说 head 是一个包含 tqh_first 与 tqh_last 的节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 TAILQ_HEAD (event_list, event); #define TAILQ_HEAD(name, type) \ struct name { struct type *tqh_first ; struct type **tqh_last ; } #endif TAILQ_ENTRY(event) #define TAILQ_ENTRY(type) \ struct { struct type *tqe_next ; struct type **tqe_prev ; }
TAILQ_HEAD 定义了一个名字为 event_list 的双向链表,记录了第一个节点与最后一个节点
它的删除操作
1 2 3 4 5 6 7 8 #define TAILQ_REMOVE(head, elm, field) do { \ if (((elm)->field.tqe_next) != NULL ) \ (elm)->field.tqe_next->field.tqe_prev = \ (elm)->field.tqe_prev; \ else \ (head)->tqh_last = (elm)->field.tqe_prev; \ *(elm)->field.tqe_prev = (elm)->field.tqe_next; \ } while (0 )
其中 (elm)->field 表示的是 elm 指针的成员字段 field
而 (elm)->field.tqe_next->field.tqe_prev = (elm)->field.tqe_prev; 与上面的 WRITE_ONCE(next->pprev, pprev); 效果一样
那么 *(elm)->field.tqe_prev = (elm)->field.tqe_next; 理解为 WRITE_ONCE(*pprev, next);,所以这里的 *(elm) 而不是 elm
这里不同的是,头节点记录的链表的头节点与尾节点,所以它的结构是
这样的好处是 可以同时在双向链表的头尾都进行增删操作,变成了一个双向队列 ,那为什么 linux 中的 hash 表没有弄成一个双向队列,因为新增的值直接加入到链表头,不需要头尾都都操作