创建一个协程
1 | go func()//通过go关键字启动一个协程来运行函数 |
那么它到底干了什么
1 | func newproc(siz int32, fn *funcval) { |
关键术语
并发:一个cpu上能同时执行多项任务,在很短时间内,cpu来回切换任务执行(在某段很短时间内执行程序a,然后又迅速得切换到程序b去执行),有时间上的重叠(宏观上是同时的,微观仍是顺序执行),这样看起来多个任务像是同时执行,这就是并发
并行:当系统有多个CPU时,每个CPU同一时刻都运行任务,互不抢占自己所在的CPU资源,同时进行,称为并行
进程:cpu在切换程序的时候,如果不保存上一个程序的状态(也就是context–上下文),直接切换下一个程序,就会丢失上一个程序的一系列状态,于是引入了进程这个概念,用以划分好程序运行时所需要的资源。因此进程就是一个程序运行时候的所需要的基本资源单位(也可以说是程序运行的一个实体)
线程:cpu切换多个进程的时候,会花费不少的时间,因为切换进程需要切换到内核态,而每次调度需要内核态都需要读取用户态的数据,进程一旦多起来,cpu调度会消耗一大堆资源,因此引入了线程的概念,线程本身几乎不占有资源,他们共享进程里的资源,内核调度起来不会那么像进程切换那么耗费资源
协程:协程拥有自己的寄存器上下文和栈。
协程与线程
goroutine与thread的不同
- 内存占用
- 一个 goroutine 的栈内存消耗为 2 KB(如果栈空间不够用,会自动进行扩容)。
- 一个 thread 则需要消耗 1 MB 栈内存,还需要一个被称为 “a guard page” 的区域(用于与其他thread隔离)
- 创建和销毀
-
goroutine的切换会消耗200ns(用户态,3个寄存器),相当于2400-3600条指令
-
除了使用时需要陷入内核,线程切换会消耗1000-1500ns
- 1ns平均可执行12-18条指令
当 threads 切换时,需要保存各种寄存器,以便将来恢复:
- 16 general purpose registers: 通用寄存器
- PC (Program Counter): 程序计数器
- SP (Stack Pointer): 栈指针
- segment registers: 段寄存器
- 16 XMM registers:
- FP coprocessor state
- 16 AVX registers
- all MSRs etc
而 goroutines 切换只需保存三个寄存器
- Program Counter
- Stack Pointer
- BP:基址指针寄存器,常用于在访问内存时存放内存单元的偏移地址
Thread内存堆栈
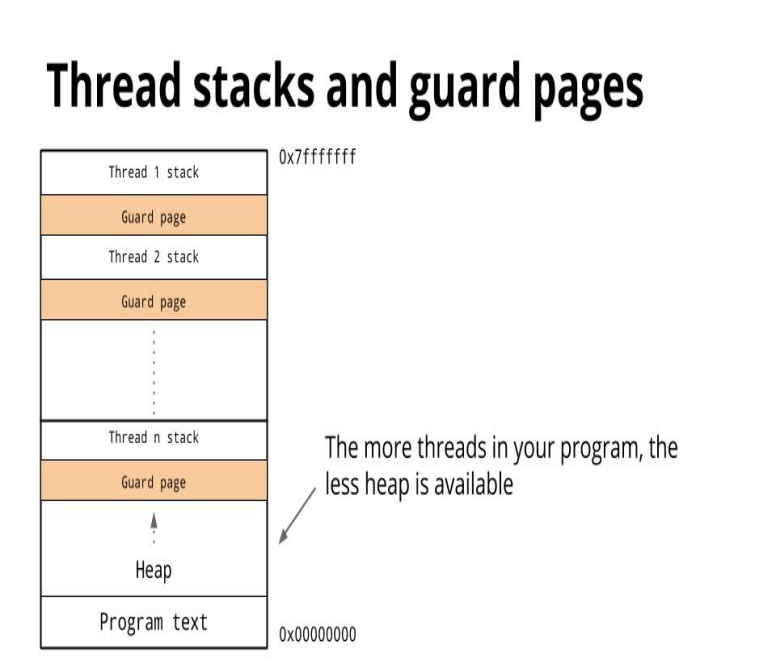
创建一个 thread 为了尽量避免极端情况下操作系统线程栈的溢出,默认会为其分配一个较大的栈内存( 1 - 8 MB 栈内存,线程标准 POSIX Thread),而且还需要一个被称为 guard page 的区域用于和其他 thread 的栈空间进行隔离。而栈内存空间一旦创建和初始化完成之后其大小就不能再有变化,这决定了在某些特殊场景下系统线程栈还是有溢出的风险
调度模型
Go 程序的执行由两层组成:Go Program,Runtime(即用户程序和运行时)
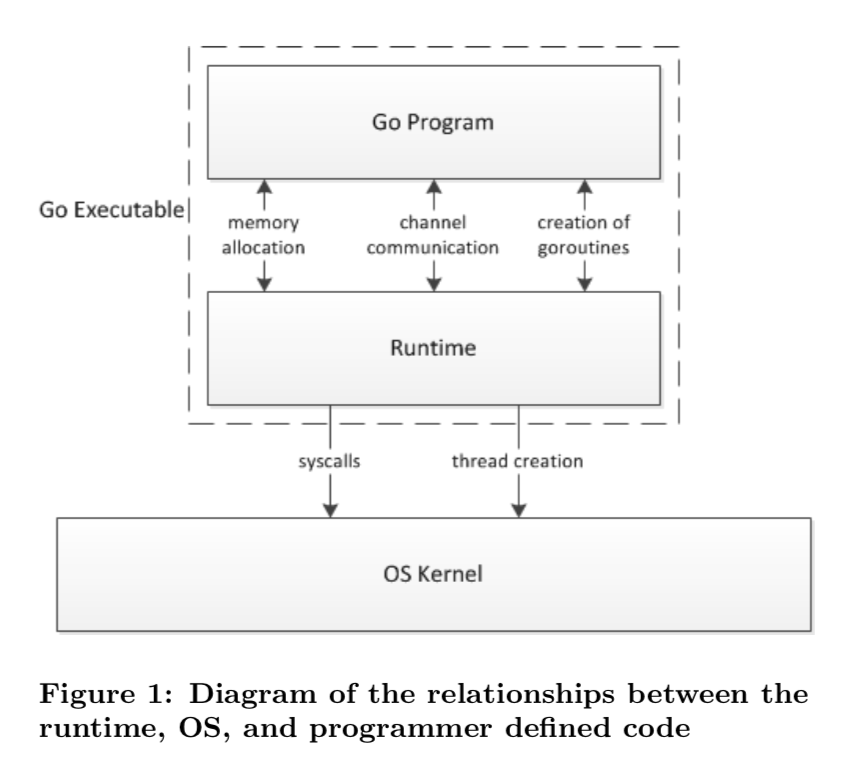
Go创建M个线程(CPU执行调度的单元,内核的task_struck),之后创建N个goroutine会依附在M个线程上执行即M:N模型。当M指定了线程栈,则M.stack->G.stack,M的PC寄存器指向G提供的函数,然后执行
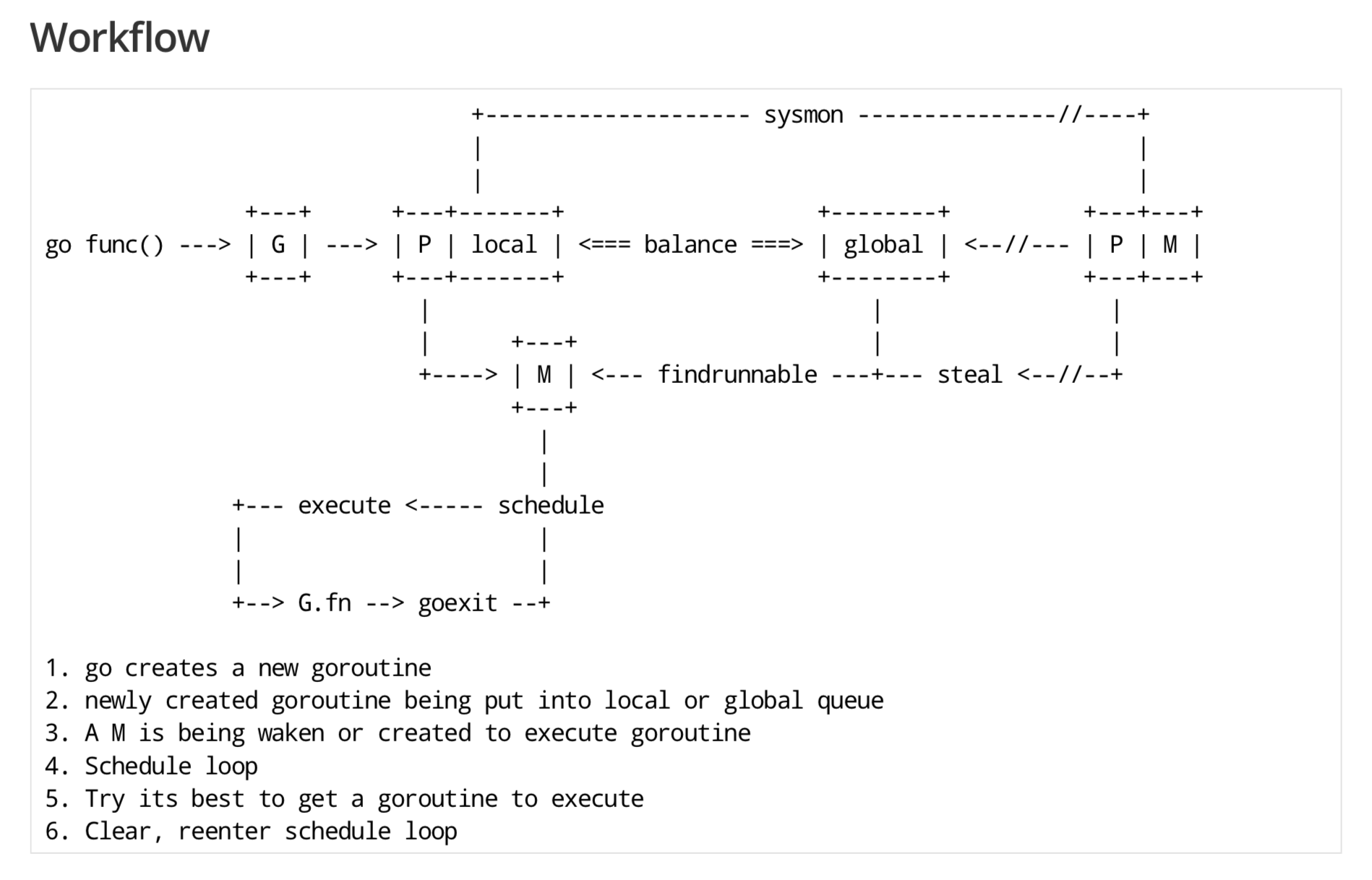
GMP
Go的调度器内部有四个重要的结构:M,P,G,Sched
- M:M代表内核级线程,一个M就是一个线程,goroutine就是跑在M之上的;M是一个很大的结构,里面维护小对象内存cache(mcache)、当前执行的goroutine、随机数发生器等等非常多的信息
- G:代表一个goroutine,它有自己的栈,instruction pointer和其他信息(正在等待的channel等等),用于调度。
- P:代表一个Processor(Core 虚拟处理器),它的主要用途就是用来执行goroutine的,维护了一个需要执行goroutine的队列(LRQ Local Run Queue)
- Sched:代表调度器,它维护有存储M和G的队列以及调度器的一些状态信息等
LRQ:本地运行队列,它属于每个处理器,以便管理分配给要执行的goroutines
GRQ:全局运行队列,存在于未分配的goroutine中
下面四种情形下,Go scheduler有机会进行调度
- 使用关键字go: go创建一个新的goroutine, Go scheduler 会考虑调度
- GC: 由于进行 GC 的 goroutine 也需要在 M 上运行,因此肯定会发生调度。当然,Go scheduler 还会做很多其他的调度,例如调度不涉及堆访问的 goroutine 来运行。GC 不管栈上的内存,只会回收堆上的内存
- 系统调用:当 goroutine 进行系统调用时,会阻塞 M,所以它会被调度走,同时一个新的 goroutine 会被调度上来
- 内存同步访问:atomic,mutex,channel 操作等会使 goroutine 阻塞,因此会被调度走。等条件满足后(例如其他 goroutine 解锁了)还会被调度上来继续运行
M:N 模型
Go runtime 会负责 goroutine 的生老病死,从创建到销毁。Runtime 会在程序启动的时候,创建 M 个线程(CPU 执行调度的单位),之后创建的 N 个 goroutine 都会依附在这 M 个线程上执行。这就是 M:N 模型:
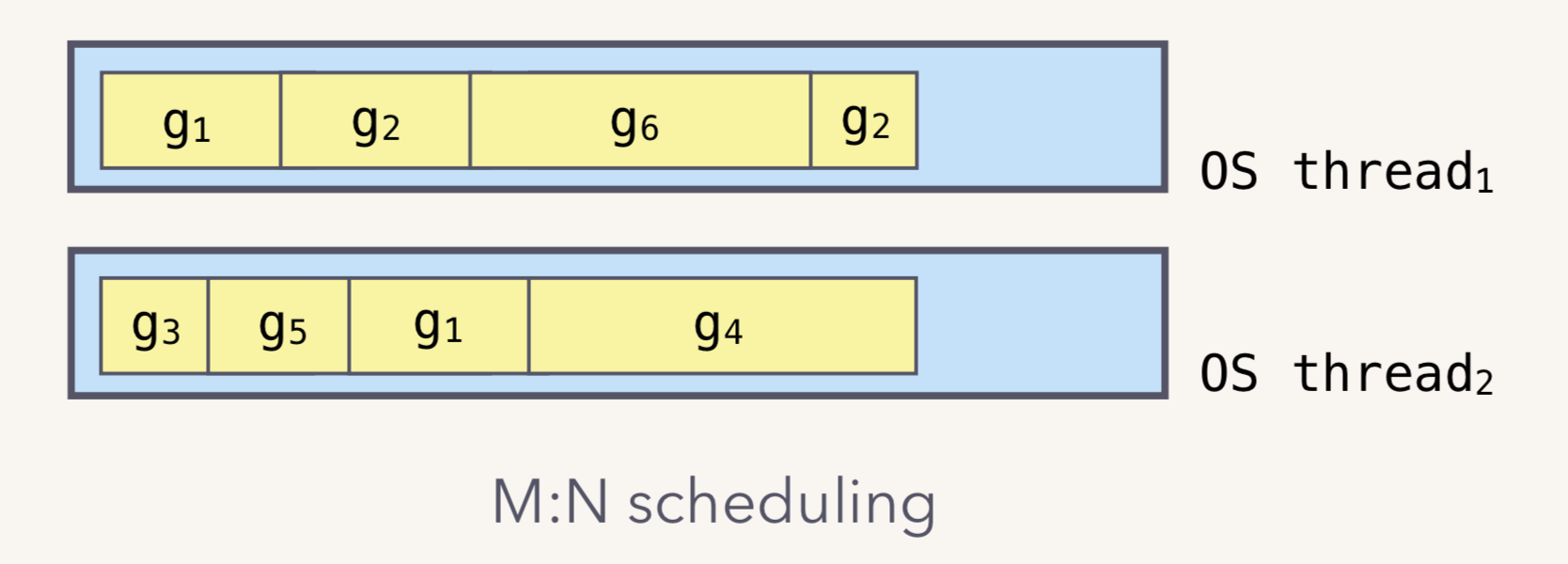
在同一时刻,一个线程上只能跑一个 goroutine。当 goroutine 发生阻塞(例如向一个 channel 发送数据,被阻塞)时,runtime 会把当前 goroutine 调度走,让其他 goroutine 来执行。目的就是不让一个线程闲着,榨干 CPU 的每一滴油水
工作窃取
Go scheduler 的职责就是将所有处于 runnable 的 goroutines 均匀分布到在 P 上运行的 M。当一个 P 发现自己的 LRQ 已经没有 G 时,会从其他 P “偷” 一些 G 来运行。这被称为 Work-stealing
Go scheduler 使用 M:N 模型,在任一时刻,M 个 goroutines(G) 要分配到 N 个内核线程(M),这些 M 跑在个数最多为 GOMAXPROCS 的逻辑处理器(P)上。每个 M 必须依附于一个 P,每个 P 在同一时刻只能运行一个 M。如果 P 上的 M 阻塞了,那它就需要其他的 M 来运行 P 的 LRQ 里的 goroutines
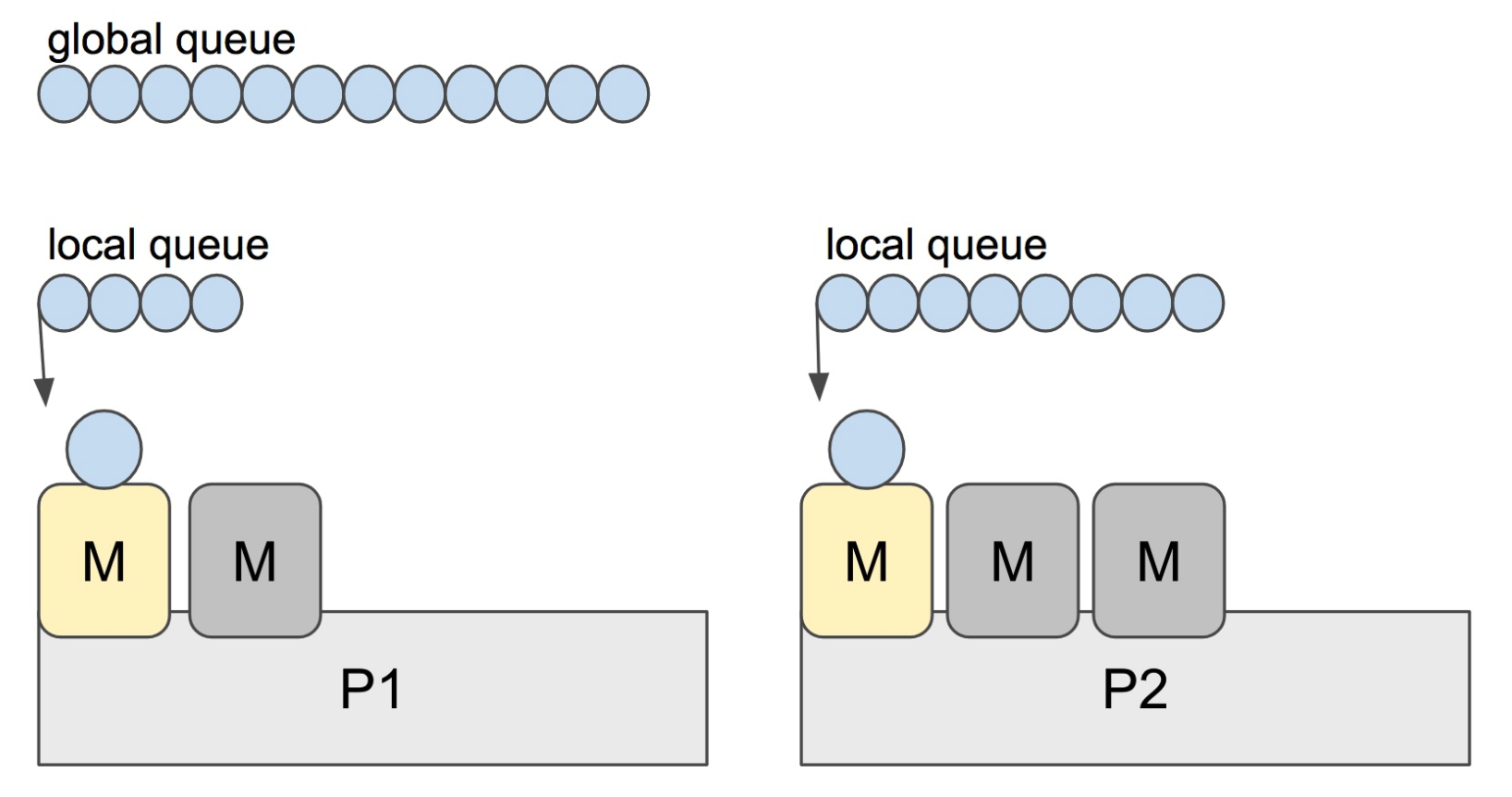
Go scheduler 每一轮调度要做的工作就是找到处于 runnable 的 goroutines,并执行它。找的顺序如下:
1 | runtime.schedule() { |
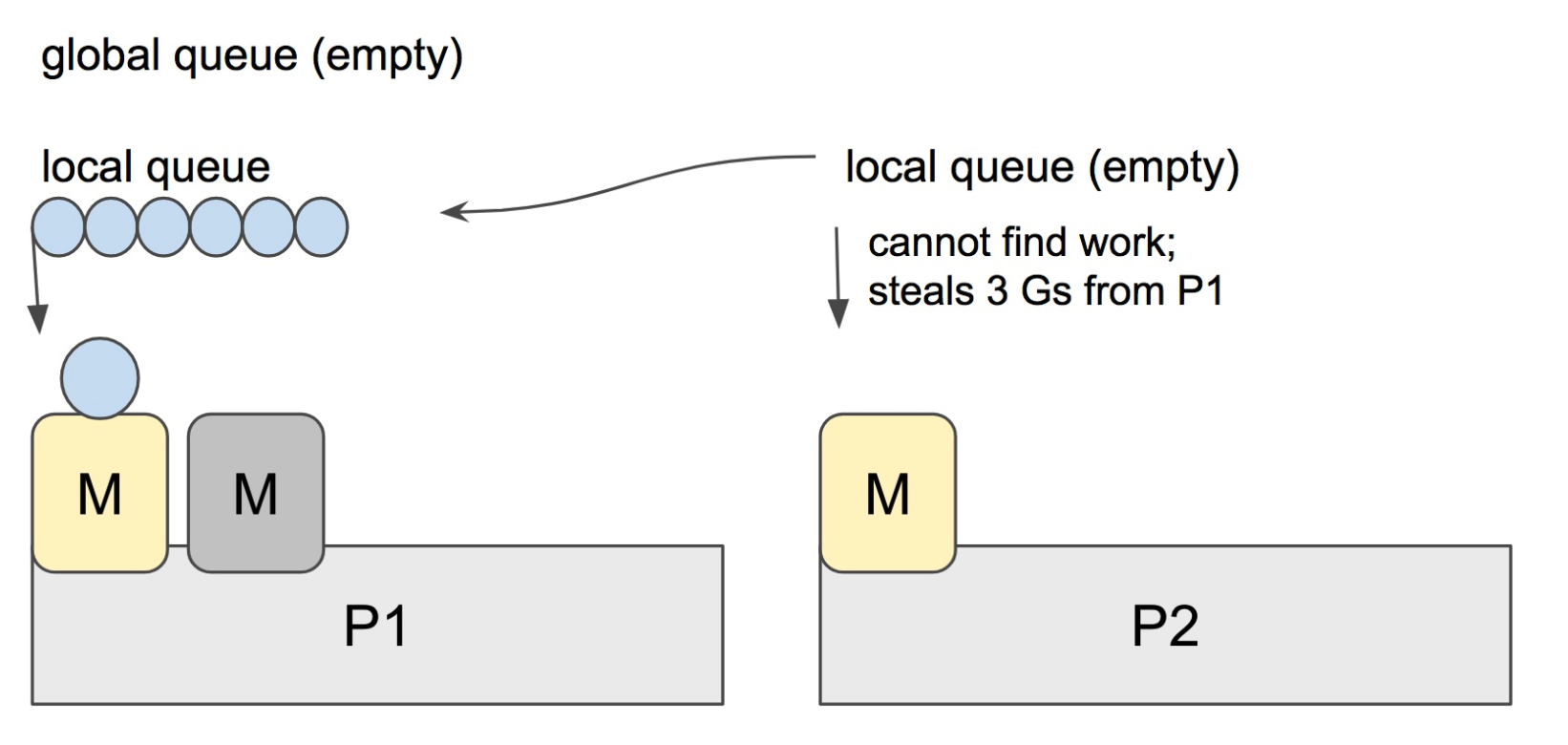
找到一个可执行的 goroutine 后,就会一直执行下去,直到被阻塞
当 P2 上的一个 G 执行结束,就会去 LRQ 获取下一个 G 来执行。如果 LRQ 已经空了,就是说本地可运行队列已经没有 G 需要执行,并且这时 GRQ 也没有 G 了。这时,P2 会随机选择一个 P(称为 P1),P2 会从 P1 的 LRQ “偷”过来一半的 G
状态切换
GPM 共同成就 Go scheduler。G 需要在 M 上才能运行,M 依赖 P 提供的资源,P 则持有待运行的 G。
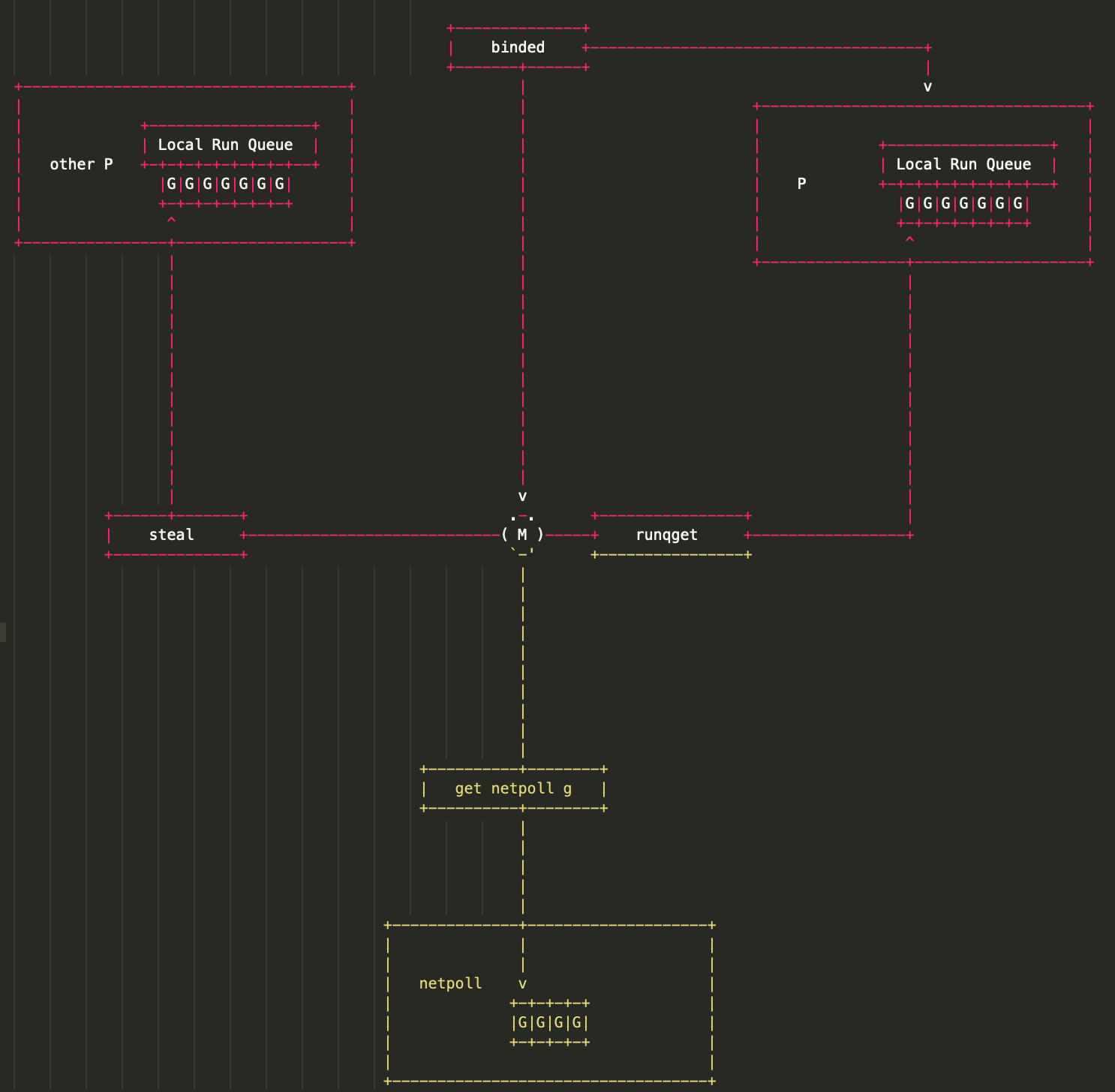
M 会从与它绑定的 P 的本地队列获取可运行的 G,也会从 network poller 里获取可运行的 G,还会从其他 P 偷 G
G 的状态流转:
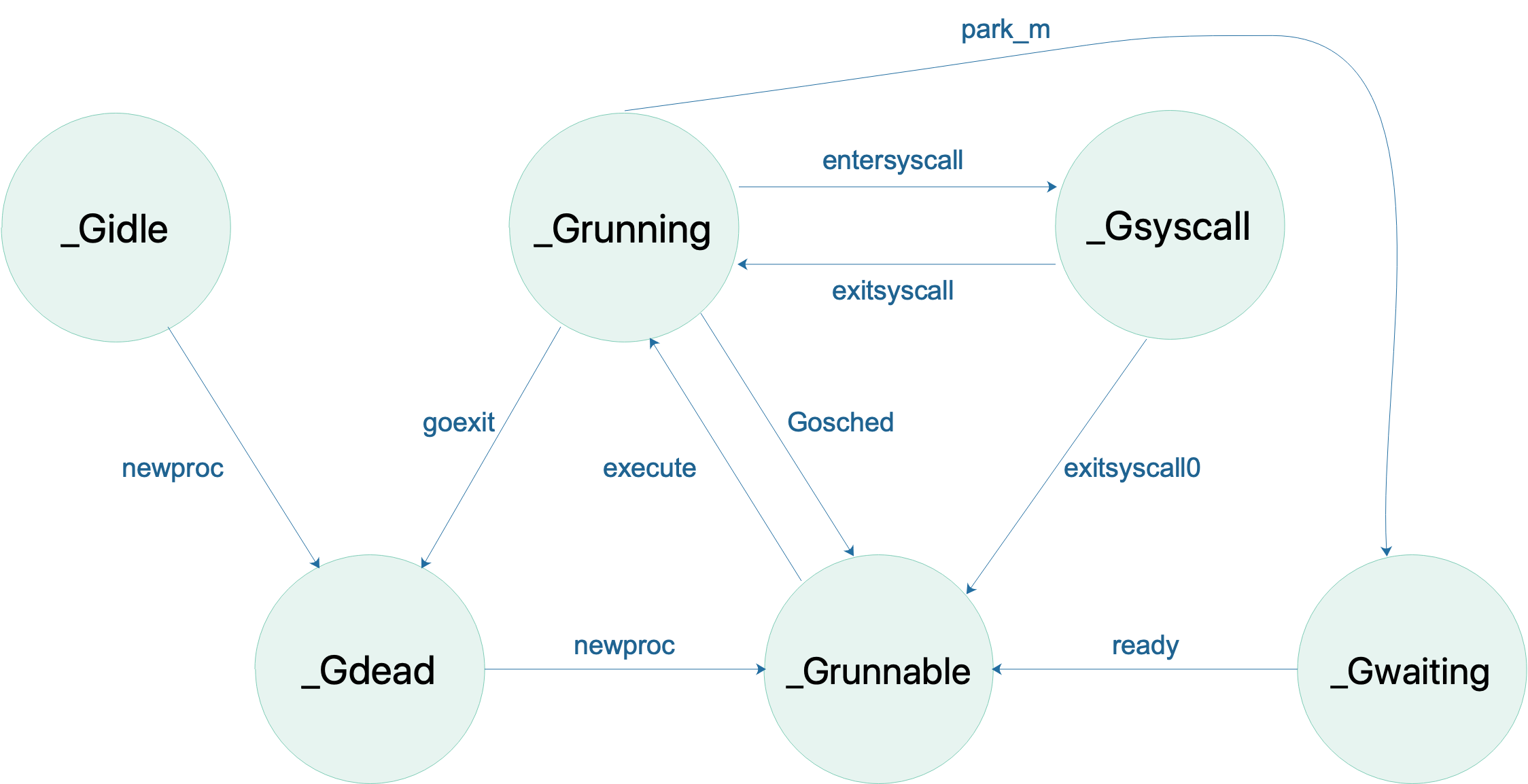
省略了一些垃圾回收的状态
P 的状态流转:
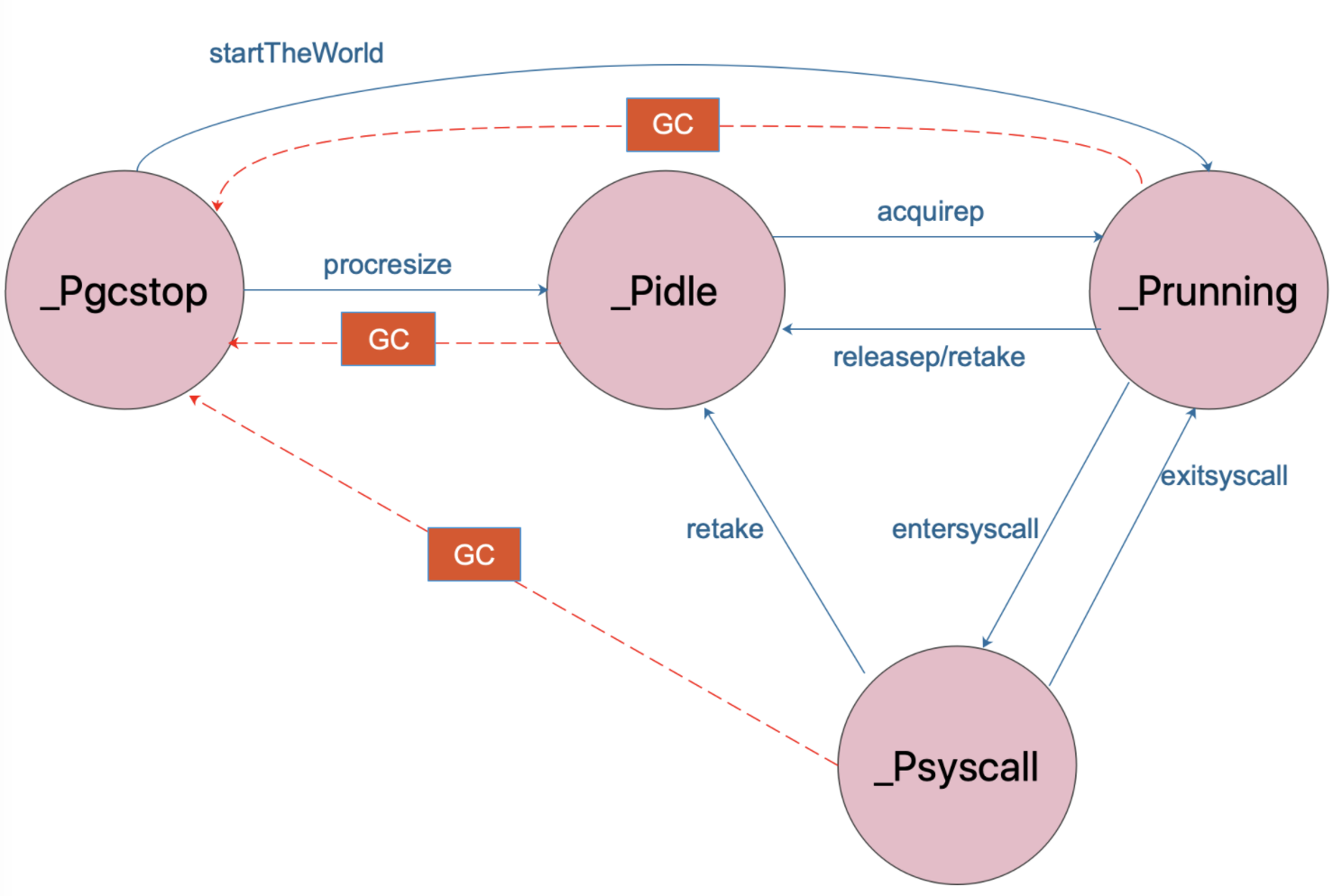
通常情况下(在程序运行时不调整 P 的个数),P 只会在上图中的四种状态下进行切换。
当程序刚开始运行进行初始化时,所有的 P 都处于 _Pgcstop 状态, 随着 P 的初始化(runtime.procresize),会被置于 _Pidle。
当 M 需要运行时,会 runtime.acquirep 来使 P 变成 Prunning 状态,并通过 runtime.releasep 来释放。
当 G 执行时需要进入系统调用,P 会被设置为 _Psyscall, 如果这个时候被系统监控抢夺(runtime.retake),则 P 会被重新修改为 _Pidle。
如果在程序运行中发生 GC,则 P 会被设置为 _Pgcstop, 并在 runtime.startTheWorld 时重新调整为 _Prunning
M 的状态变化:

M 只有自旋和非自旋两种状态。自旋的时候,会努力找工作;找不到的时候会进入非自旋状态,之后会休眠,直到有工作需要处理时,被其他工作线程唤醒,又进入自旋状态
调度器
Go调度程序不是抢占式调度程序,而是协作式调度程序。 成为协作调度程序意味着调度程序需要在代码的安全点明确定义用户空间事件,以制定调度决策。 以下是调度的关键点:
-
启动协程的关键字
go -
垃圾回收GC
-
系统调用
- 对于异步系统调用例如网络请求,将可能阻止的goroutine移到网络轮询器,让处理程序可以执行下一个
- 处理像文件IO同步请求,当前的G和M对将与G,P,M模型分开。 同时,将创建一台新机器,以保持原始的G,P,M模型正常工作,并且在系统调用完成时将收回块goroutine
地鼠(gopher)用小车运着一堆待加工的砖。M就可以看作图中的地鼠,P就是小车,G就是小车里装的砖。一图胜千言啊,弄清楚了它们三者的关系,下面我们就开始重点聊地鼠是如何在搬运砖块的
启动过程
- runtime·schedinit 调度器初始化:主要是根据用户设置的GOMAXPROCS来创建一批小车(P),不管设置多大,最多也只能创建256个小车(P)。这些小车(p)初始创建好后都是闲置状态,也就是还没开始使用,所以它们都放置在调度器结构(Sched)的pidle字段维护的链表中存储起来了,以备后续之需。
- runtime.newproc 创建一个协程
- runtime.main
- runtime·mstart
源码阅读
G
1 | type g struct { |
其中g结构体关联了两个比较简单的结构体,stack 表示 goroutine 运行时的栈
1 | // 描述栈的数据结构,栈的范围:[lo, hi) |
M
再来看 M,取 machine 的首字母,它代表一个工作线程,或者说系统线程。G 需要调度到 M 上才能运行,M 是真正工作的人。结构体 m 就是我们常说的 M,它保存了 M 自身使用的栈信息、当前正在 M 上执行的 G 信息、与之绑定的 P 信息……
当 M 没有工作可做的时候,在它休眠前,会“自旋”地来找工作:检查全局队列,查看 network poller,试图执行 gc 任务,或者“偷”工作
1 | // m 代表工作线程,保存了自身使用的栈信息 |
P
1 | type p struct { |
Sched
Go scheduler 在源码中的结构体为 schedt,保存调度器的状态信息、全局的可运行 G 队列等
1 | // 保存调度器的信息 |
还有一些重要的常量
1 | // 所有 g 的长度 |
参考文献:
- https://colobu.com/2017/05/04/golang-runtime-scheduler/
- http://morsmachine.dk/go-scheduler
- https://www.zhihu.com/question/20862617
- https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part2.html
- https://www.bookstack.cn/read/go-internals/zh-05.1.md
- https://golang.design/go-questions/sched/goroutine-vs-thread/
- https://learnku.com/articles/41728
- https://www.codercto.com/a/38162.html
- https://www.cnblogs.com/flhs/p/12677335.html