之前在整理 GoZero4-协程池的过程中发现 字节跳动开源的协程池在使用中需要注意的地方:
使用双向链表存储任务,表示它理论上支持无限个任务。后面的任务可能存在长时间等待的情况,并不存在任务过期处理逻辑
没想到在实际应用中真的没注意踩了一遍,这里记录一下这个原因与后续的解决思路,排查过程就不赘述了。
伪代码如下:
1 | //伪代码 |
问题原因:负责底层通信的 grpc-go(进行过二次开发) 使用了上述的协程池进行发送接口的超时控制。当突然大量的消息进入,消息接受速率 大于 消息发送-响应速率。导致过量的消息全部堆积到这个双向链表中,而本身消息是有超时时间的,就导致堆积的消息越来越多,消息等到发送的时候已经超时了,所以就出现了服务OOM,消息也无法发送出去。
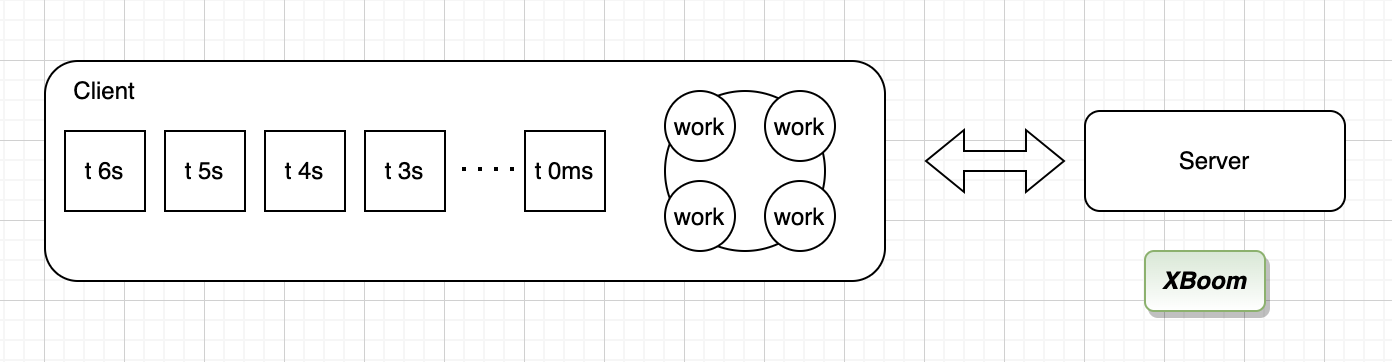
类似上图所示,模拟客户端通过协程池的发送协程 work 实现超时控制消息任务 t 的发送
- 第一阶段,发送协程 work 的消费速率 大于 消息任务 t 的生产速率,一切正常
- 第二阶段,发送协程 work 的消费速率 小于 消息任务 t 的生产速率的时候,消息开始在双向链表中堆积,出现内存快速增长
- 第三阶段,当 消息任务 t 的堆积 超过自定义超时时间的时候,所有消息都发送超时失败
- 第四阶段,当 双向链表中的任务堆积导致内存超时服务上限的时候,服务OOM
这里产生了如下几个思考
- 能否在任务双向链表中限制数量大小当发送超过限制的时候直接失败?
- 为什么不直接使用管道来代替底层的双向链表?
- 能否自动丢弃超时的消息并返回结果,注意这个时候是在协程里面运行的
- 如何像linux一样保存 pod因为OOM而产生的core方便后续分析
第一个问题是可以解决的,协程池对象存在 taskCount 记录当前任务数量,也就是说可以增加协程池容量判断来达到限制目的
- 增加协程池任务容量字段
taskCap - 增加接口,协程失败返回错误 error
- 添加协程池容量判断
1 | func (p *pool) CtxGo2(ctx context.Context, f func()) error { |
第二个问题管道的缺点是管道数量是固定的,也就是达不到根据任务数量动态扩容 work 的功效
第三个问题由于任务放入协程中相当于异步处理,并不能直接将任务待执行超时的情况返回给客户端,可以通过自定义处理函数或者内部的panic处理任务超时的情况;但又能如何发现任务超时,时间轮貌似是个好东西
第四个问题找到一篇实践,实操之后再单独记录
总结:
- 我在使用过程中忽视了双向队列任务堆积的情况,令牌桶的使用也可能存在这样的情况(正常情况不会配置速率上千万的情况),注意异常情况下的配置范围
- 上述需要改进与实操的部分尝试解决之后再来补充这边文章