一开始以为 Sync.Map 仅仅是封装的了一层,后来在与同事的讨论中发现并不是这样,这里重新学习一下源码
线程安全
首先搞清楚一个问题,什么是并发安全。由于没有完整的解释,我找了一段Java中的表达
当多个线程访问某个类时,不管运行环境采用何种调度方式或者这些进程将如何交替执行,并且在主调代码中不需要任何额外的协同或者同步,这个类都能表现出正确的行为,那么这个类是线程安全的
大致抓住两点 无论如何交替执行 表现出正确的行为,有点抽象,反过来问 什么情况会导致线程不安全?怎样才能保证线程安全?
当前的一个操作可能不是原子的,执行过程中会被打断,其他线程有能力修改共享变量的值,同时存在线程修改的值不是立即对其他线程可见的,因为线程有自己的执行空间,另外一点就是存在程序可能存在乱序执行的情况,单线程没问题,但是多个线程同时执行,线程共享的数据会出现错乱。那么保证线程安全的三个特征:
- 原子性:提供互斥访问、同一时刻只能有一个线程在操作
- 可见性:一个线程对主内容的修改可以及时被其他线程看到
- 有序性:程序在执行的时候,程序的代码执行顺序和语句的顺序是一致的有序性
- 多个协程并发执行,那么几个协程之间是没有有序性的,但是协程里面的代码是有序的
- 什么情况下代码的执行顺序与语句顺序不一致?比如指令重排序,将多次访问主存合并到一起执行
这样就好理解为啥普通的map会存在并发安全问题了,因为一个协程的修改对于另外一个协程可能是不可见的。另外当map并发读写时候触发的panic是map内部实现的,结构体的并发读写只会报错不会panic。
使用
普通的map并发处理实践
1 | var counter = struct{ |
使用 sync.Map 则可以
1 | var counter sync.Map |
实现原理
源码:src/sync/map.go
为了实现并发安全的Map,Sync.Map实现了一种读写分离的方式
- 空间换时间。 通过冗余的两个数据结构(read、dirty),实现加锁对性能的影响。
- 动态调整,miss次数多了之后,将dirty数据提升为read。
- double-checking,因为是判断与获取并不是原子操作,所以会出现 double-checking
- 延迟删除。 删除一个键值只是打标记,只有在提升dirty的时候才清理删除的数据。
- 优先从read读取、更新、删除,因为对read的读取不需要锁。
问题1:如何在并发情况下修改或删除已经存在的Key?
答:通过将 key 映射到 val 的地址,然后 val 指针指向真正的值,那么只需要保证 address 指针的原子操作,就能解决并发安全问题
key -> &地址 --> 真正的值
问题2:如何在写的同时保证读的准确性
答:读写指向的是同一个指针,首先在写时会通过互斥锁防止并发操作 dirty,其次就是用到了atomic原子操作value指针
问题3:如果读写分离,如何将写入的数据同步到读中
答: 1. 第一种是当misses == len(dirty)的时候就会升级dirty到read中;第二种就是在遍历的如果dirty有read中没有的数据;
第三其实也不是读写分离,而是乐观锁,因为如果read中已经有key/val,也会尝试去更新read,发现已经删除,则去dirty中更新
最后的实现就变成了下面这个样子
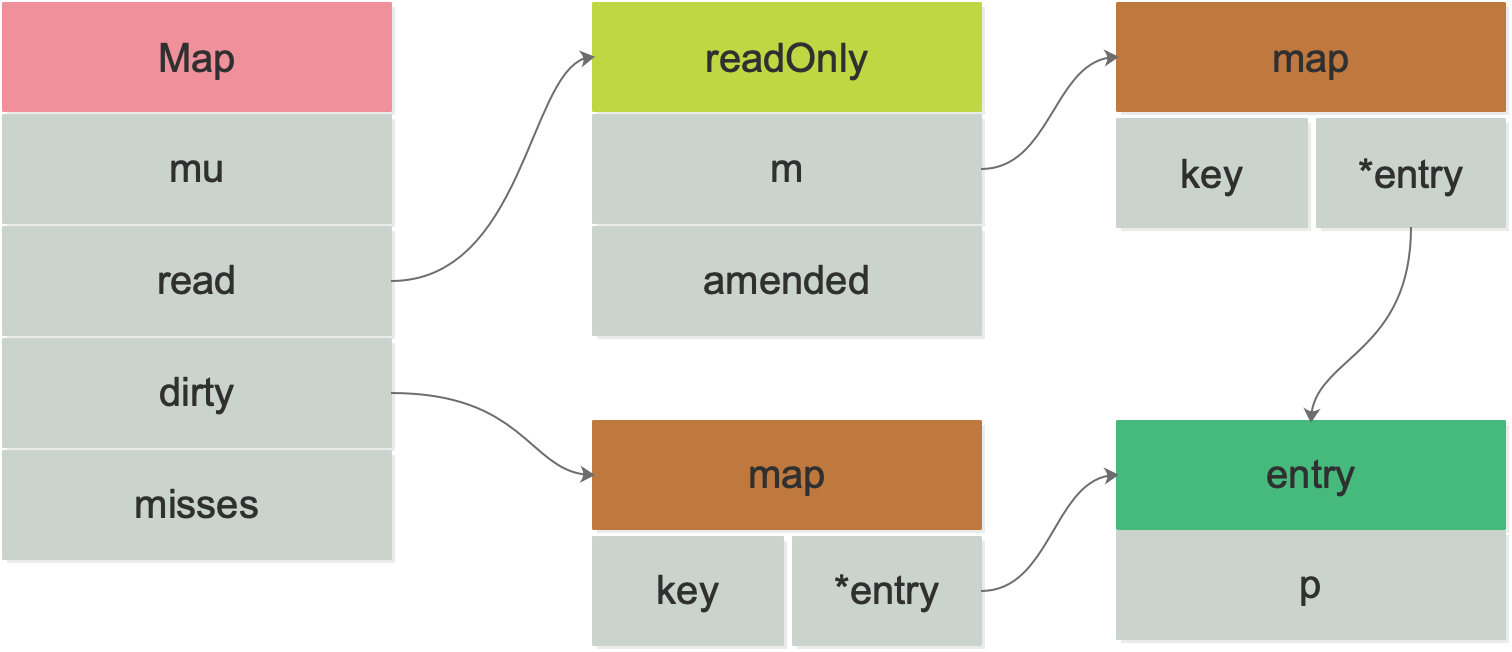
问题4:指向的是同一个entry,不还是一样需要加锁吗?内部 的mutex 与 atomic.pointer的区别跟作用又是什么?
mutex 与 atomic 的区别是:mutex 通过阻塞其他协程起到了原子操作的功能,是用来保护 dirty 的读写的。而atomic是通过CPU指令,来达到值操作的原子性,所以 atomic与mutex并不是一个层面的东西,atomic也比mutex更快。
所以才会出现 mutex 保护的是 dirty,而 atomic 保护的是 entry 具体值
数据结构
定义的 Map 中 除普通的map 与 互斥锁,还增加了两个字段
1 | type Map struct { |
其中存在两个结构
1 | type readOnly struct { |
基本
read与dirty的转换entry的操作
entry
entry 代表的是每个 key 在Map中对应的一个 entry,并且还记录了 其他信息
1 | type entry struct { |
p 一共记录林 entry 的三种状态
nil:entry已被删除了,并且m.dirty为nilexpunged:entry已被删除了,并且m.dirty不为nil,而且这个entry不存在于m.dirty中- 其它:
entry是一个正常的值
构建一个 entry 如下:
1 | func newEntry(i any) *entry { |
entry 使用 atomic.Pointer[n] 的作用在后面才体现出来, atomic.Pointer 原子地读取和存储指针类型的值
1 | func (e *entry) trySwap(i *any) (*any, bool) { |
操作
操作与正常的map类似,包含 存储、获取、删除、遍历。除此之外还增加的 交换、比较交换、比较删除
获取
1 | func (m *Map) Load(key any) (value any, ok bool) { |
这里有两个注意事项
-
出现double-check,是因为在执行
if !ok && read.amended的过程中,dirty可能升级为read,所以还是需要锁操作 -
不管 m.dirty中是否存在,都需要misses+1,表明 read中不存在才到 dirty中获取
1
2
3
4
5
6
7
8
9func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
m.read.Store(&readOnly{m: m.dirty}) //直接将dirty升级到read中,然后
m.dirty = nil
m.misses = 0
}
什么时候讲dirty提升为 read,当 misses >= len(m.dirty)
存储
从接口实现可以看出,存储 k/v 内部使用的其实 Swap 接口
1 | func (m *Map) Store(key, value any) { |
直接查看 Swap 的实现原理
根据描述,Swap 的作用是 将 newValue 更新入 key 所对应的 value中,并将 oldValue 返回。另外一个返回值loaded表示 key 是否存在
1 | func (m *Map) Swap(key, value any) (previous any, loaded bool) { |
这里 dirtyLocked的作用是将未删除的复制到dirty中
1 | func (m *Map) dirtyLocked() { |
删除
1 | func (m *Map) Delete(key any) { |
如果read中存在,那么仅会标记删除
1 | func (e *entry) delete() (value any, ok bool) { |
遍历
因为是读写分离,所以在遍历的过程中
- 如果dirty中没有新数据,那么就使用read遍历
- 如果dirty中有新数据,那么就将dirty升级为read,然后遍历read
1 | func (m *Map) Range(f func(key, value any) bool) { |
总结:
-
该map仅针对特定的场景
- Key 读多写少的情况,例如只增长的缓存
- 多个协程针对不同的key合集进行读写更新时候可以用
- sync.Map 不能在第一次使用后复制
-
由于dirty达到一定条件就需要升级为read,所以适用读多写少的场景