在学习分布式系统过程中,经常能碰到一致性算法,即使出现部分节点故障,网络延时等情况,也不影响整体可用性,进而提高系统的整体可用性。Raft协议是一种分布式一致性算法(共识算法),共识就是多个节点对某一个事件达成一致的算法,常见的一致性协议有Raft、Paxos、ZAB,根据 《ETCD 技术内幕》 学习 Raft 协议
基本定义
Raft 为了实现共识,会选举出主从节点,任意节点都处于下面3类角色:
- Leader(领袖):领袖由群众投票选举得出,每次选举,只能选出一名领袖;
- Candidate(候选人):当没有领袖时,某些群众可以成为候选人,然后去竞争领袖的位置;
- Follower(群众):相对于 Leader 来说,在非选举过程中的其他节点就是 Follower,任何节点都可能通过 Candidate 成为 Leader
在进行选举过程中,还有几个重要的概念:
- Leader Election(领导人选举):简称选举,就是指选出 Leader;
- Term(任期):其实是一个单独递增的连续数字,每一次任期就会重新发起一次 Leader Election,每个节点都会记录当前的任期值
- Election Timeout(选举超时):就是一个超时时间,当 Follower 超时未收到 Leader 的心跳时,会重新进行选举
任期(Term):实际上是一个全局的、连续递增的整数。在raft中,每进行一次选举,任期就会+1
节点存在三种状态分别是:
- Leader节点:可读可写、处理日志复制、保证⼀致性、维护⼼跳
- Follower节点:可进行读操作,写操作需要路由到Leader处理;参与投票,⼀个term任期内只能投⼀次; 当触发 election timeout 时,晋升为 Candidate
- Candidate节点:集群的候选者,会发起投票试图当选leader ; 通过
RequestVote通知其他节点来投票;
集群中任意一个节点都处于这三个状态之一
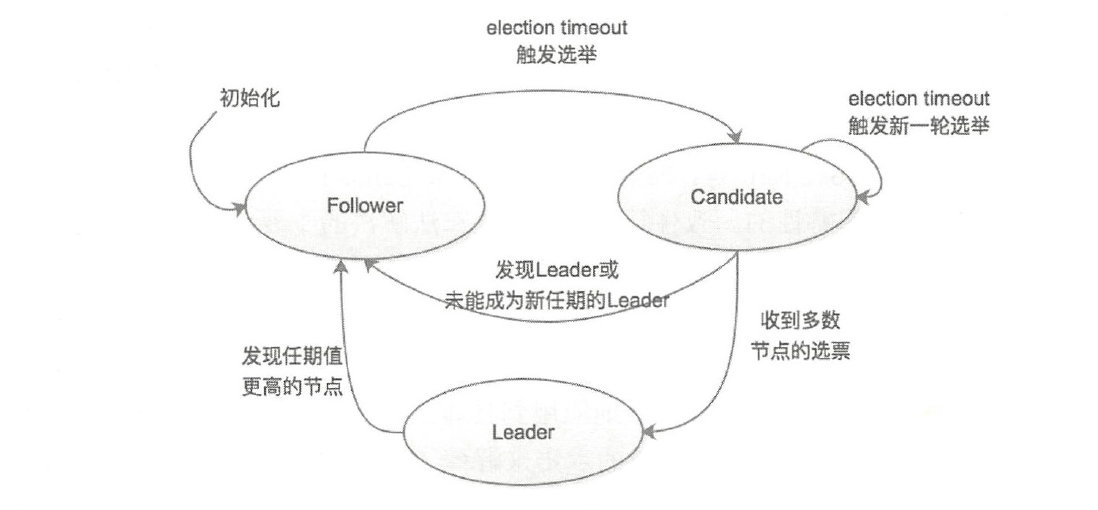
如上图所示
-
当 Etcd节点刚启动的时候,节点初始化状态为 Follower
-
为了进行 Leader Election 有两个时间
- 选举超时时间(Election timeout): 每个 Follower 节点在接收不到 Leader 节点的心跳消息之后,并不会立即发起新一轮选举,而是需要等待一段时间之后才切换成 Candidate 状态发起新一轮选举。是一个一定范围的随机数,为了保证各节点不是同时发起选举请求
- 心跳超时时间(Heartbeat timeout): Leader节点向集群中其他Follower节点发送心跳消息的时间间隔
-
-
Leader选举
能成为 Leader 的条件有
- 当前集群⽆可用 leader
- 触发 Election timeout
- Term 任期最新
- Log 日志最新
- 获取多数投票

流程可以查看:http://thesecretlivesofdata.com/raft/
需要注意的是:
- 超过集群半数节点应答,才将日志写入WAL中,也是就如果没有等到半数应答就挂了,那么数据就丢了
- Follower 收到 Leader 的 复制日志 则直接将日志写入 WAL 中
- 当Follower收到 Vote Request 也会重置 election timeout 定时器(降低同时出现两个候选人的概率)
- Term 将持续直到某个节点因为心跳超时而从新发起选举
- 出现多个候选人都没有称为 Leader,那么选举失败,切换为Follower,等待下一个选举超时
- Leader 宕机后,其他节点重新选出新 Leader。等到旧Leader 恢复,会因为收到新Leader心跳 而自己的 Term 落后,切换成 Follower,更新自己的Term,然后重新投出自己的选票
基本流程
将设ETCD集群中有三个节点(A、B、C)

- 初始化,所有节点起初都是 Follower 状态(Term = 0, 得票数 = 0)
- 节点 A 由于长时间未收到 Leader 的心跳消息,就会切换成为 Candidate 状态并发起选举
- 节点 A 的选举计时器 Election Timer 己被重置
- 节点 A 首先会将自己的选票投给自己,并会向集群中其他节点发送选举请求 **Request Vote **以获取其选票,此时节点会有几种状态
- 当前状态是 Leader(初始化的时候不会)
- 当前状态是 Candidate,当处于 Candidate 状态而收到
Request Vote的时候,如果接收到 Term 值比自身记录的 Term 值大的请求时,节点会切换成 Follower 状态井更新自身记录的 Term 值 - 当前状态是 Follower,此时的节点 B 和节点 C 还都是处于 Term=0 的任期之中,且都是 Follower 状态,均未投出 Term=1 任期中的选票,所以节点 B 和节点 C 在接收到节点 A 的选举请求后会将选票投给节点 A,任期变为1
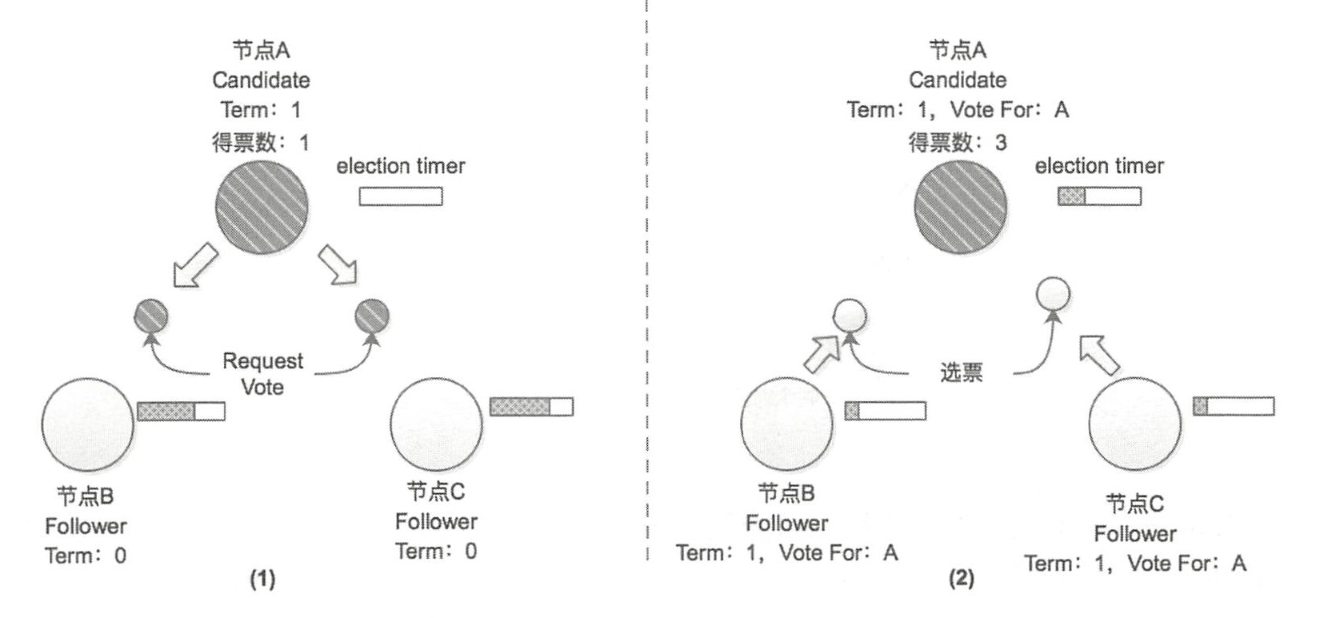
-
在节点 A 收到节点 B、 C 的投票之后,其收到了集群中超过半数的选票,所以在 Term = 1 的任期中,该集群的 Leader 节点就是节点 A,其他节点将切换成 Follower 状态,
节点除了记录当期任期号(CurrentTerm),还记录在该任期中当前节点的投票结果(VoteFor)
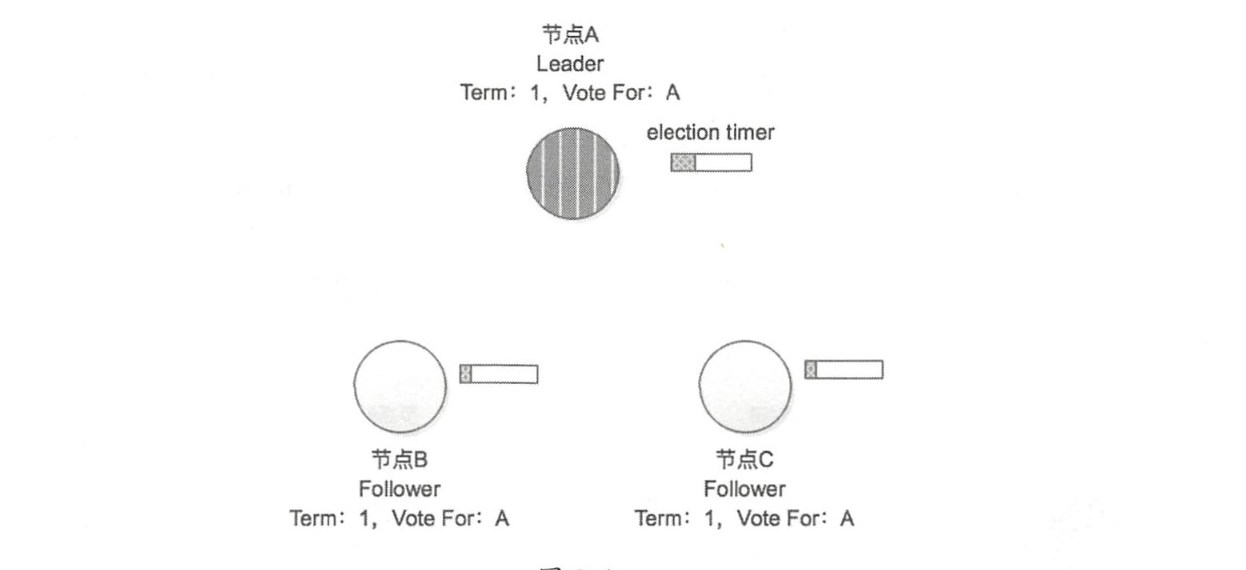
-
成为 Term = 1 任期的 Leader 节点之后,节点 A 会定期向集群中的其他节点发送心跳消息,防止节点 B 和节点 C 中的选举计时器Election timer 超时而触发新一轮的选举(重置定时器),此时当前节点的状态
- 当前状态是 Follower,当节点 B 和节点 C (Follower) 收到节点 A 的心跳消息之后会重置选举计时器,更新 Term
- 当前状态是 Candidate, 当处于 Candidate 状态而收到
Request Vote的时候,如果接收到 Term 值比自身记录的 Term 值大的请求时,节点会切换成 Follower 状态井更新自身记录的 Term 值
心跳超时时间(heartbeat timeout)需要远小于选举超时时间(election timeout)
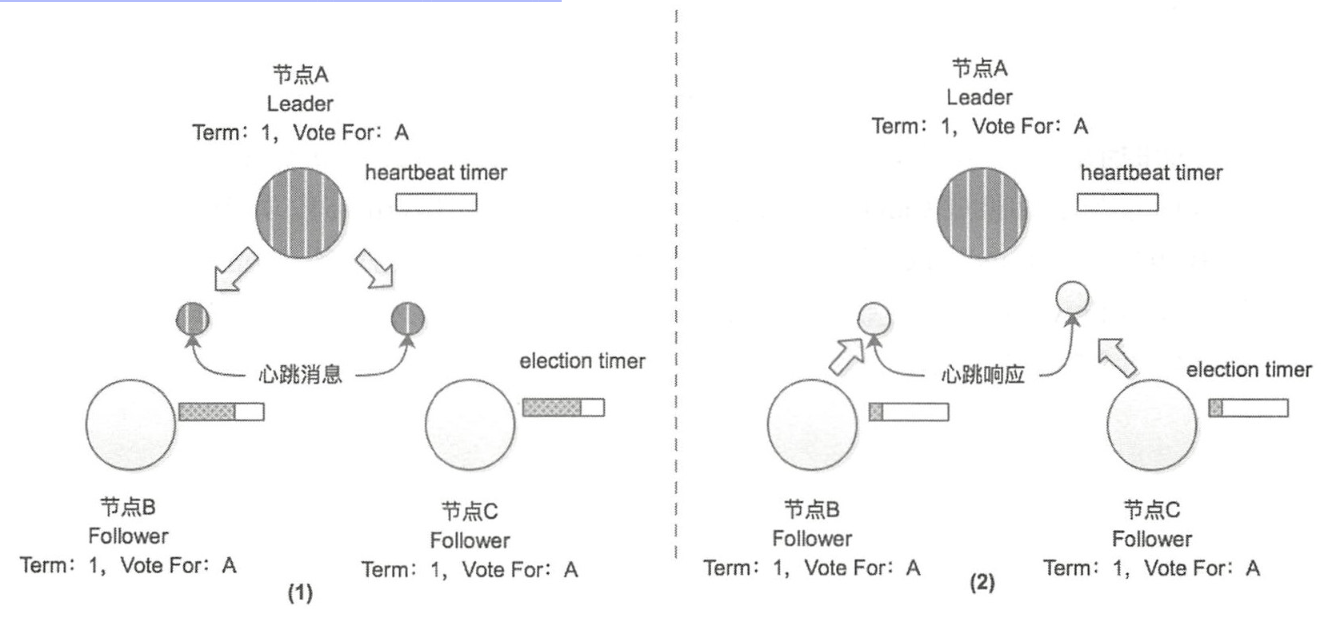
Candidate 发起选举前,会先尝试连接集群中的其他节点。如果连接不上,放弃本次选举。这个状态称之为:Prevote
带着问题看世界
-
如果Leader节点频繁宕机,或者选举反复进行,怎么办?
答:要求 心跳超时时间 << 选举超时时间 << 平均故障间隔时间
-
心跳超时时间:节点直接发送心跳信息的完整返回时间 Hearthbeat timeout:0.5ms~50ms
-
选举超时时间:election timer:200ms~1s
-
故障间隔时间:两次故障的平均时间:1个月或更多(保证节点的不要经常出故障)
-
-
是不是谁先发起了选举请求,谁就得到了Leader?
答:不是,除了看先后顺序,还取决于Candidate节点日志是不是最新最全的日志,否则拒绝投票,防止出现日志(即数据)丢失的情况
-
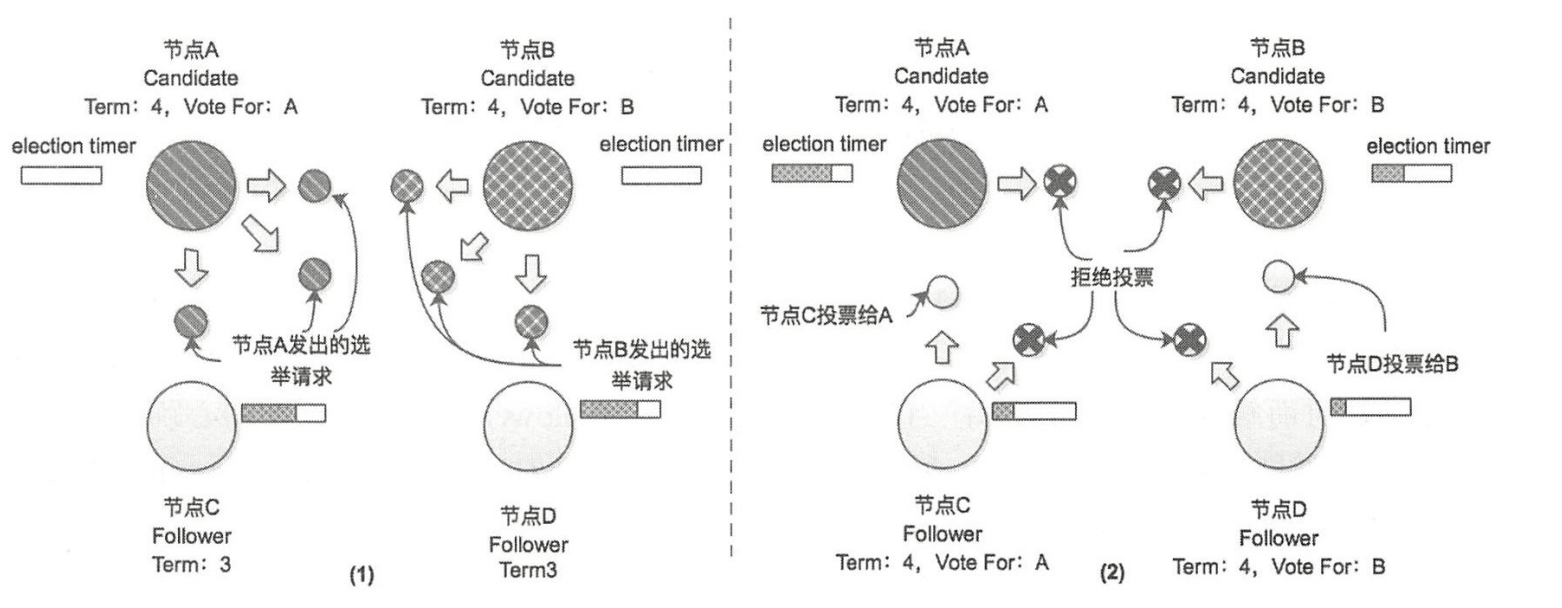
如果两个节点同时成为 Candidate 发起选举,刚好它们的日志 都是最新的是如何选举的
答:虽然每个节点的 Election Timer 都不同,但也是不能避免两个节点同时触发选举。比如有 4 个节点
异常情况
场景 1:假设A、B同时触发选举,A 的Request Vote先抵达节点 C ,B 的Request Vote先抵达节点 D,A、B 除了得到自身的选票之外,还分别得到了节点 C 和节点 D 的 Vote且票数相同没有超过半数
在这种情况下, Term = 4 这个任期会以选举失败结束,随着时间的流逝,当任意节点的 Election Timer 到期之后,会再次发起新一轮的选举。由于 election timeout 是在一个时间区间内取的随机数,所以在配置合理的时候,像上述情况多次出现的概率并不大
场景 2:假设选举已经完成, Leader 在运行过程中 Down 掉了
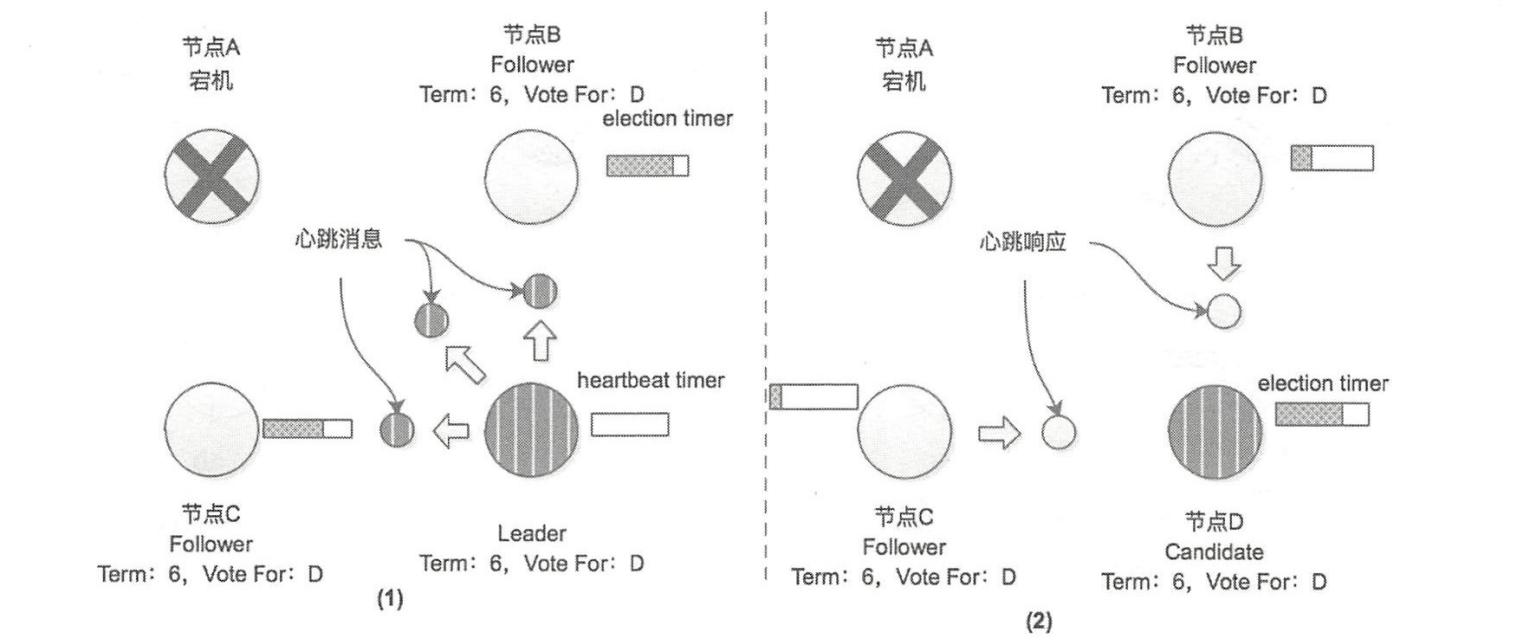
当 A 恢复之后,会收到节点 D 发来的心跳消息,该消息中携带的任期号 Term=6 > 节点 A 前记录的任期号 Term=5 ,A 切换成 Follower
并更新自身的 Term,同时重置远举计时器
场景 3:当节点与其他节点断开连接(出现网络分区),不断触发选举超时,在恢复的时候因为 Term 比较大又成了 Leader
为了防止选举超时而不断的增加 Term ,当恢复的时候因为 Term 而变成 Leader,所以采取了 Prevote 措施,变为 candidate 的条件
- 询问其他节点是否有可用 leader
- 可连通绝⼤数节点
日志复制
Leader 节点除了向 Follower 节点发送心跳消息,还会处理客户端的请求,并将客户端的写操作 以消息(Append Entries 消息)的形式发送到集群中所有Follower节点
步骤如下:
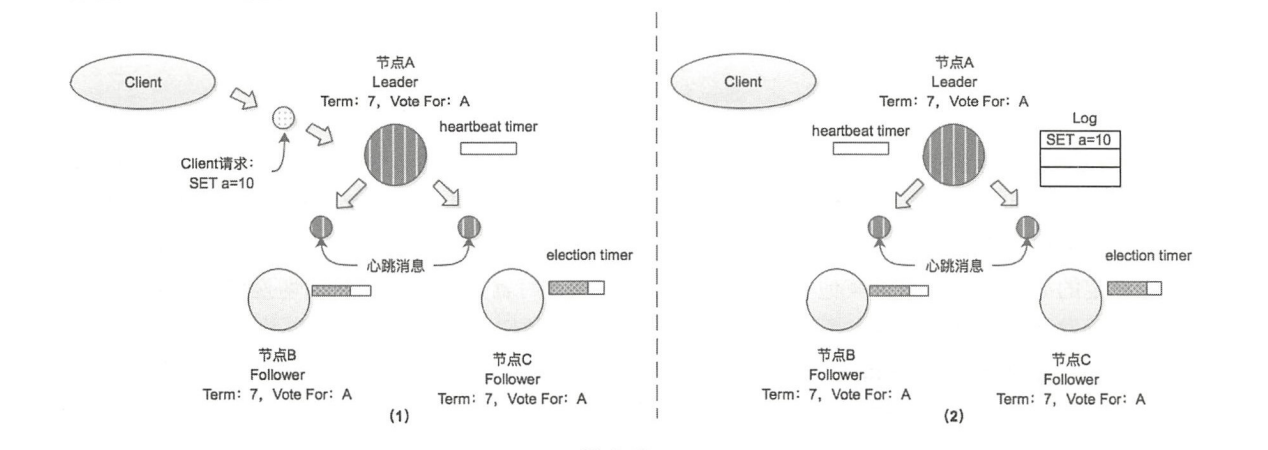
- Leader 节点接到 client 请求后
set a=10,将本请求计入本地log
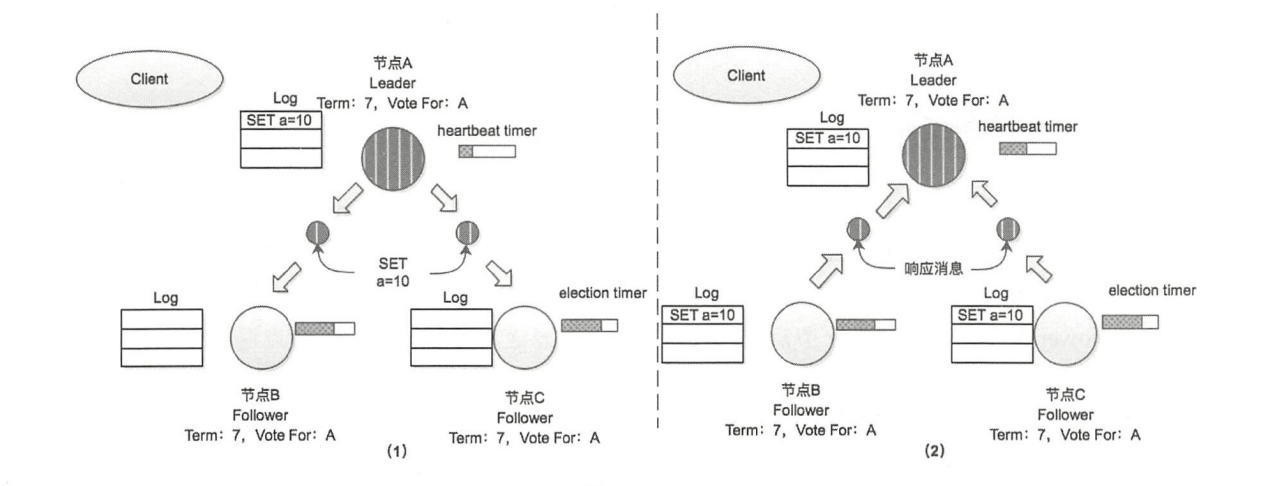
- Leader 节点向 Follower1 和 Follower2 发送Append Entries消息
set a=10 - Follower1 和 Follower2 将此信息计入本地log,并返回给 Leader
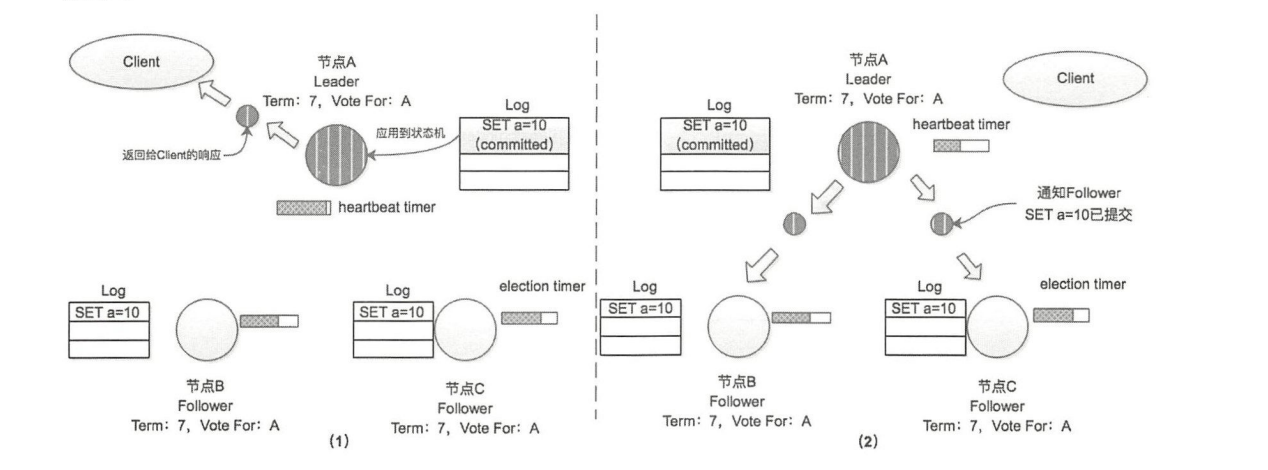
- Leader 将日志信息置为 已提交(Commited),然后状态机处理。
- 响应 client 请求
- 向 Follower1 和 Follower2 发送消息,该信息已提交
- Follower1 和 Follower2 接到消息后,修改日志状态,交给自己的状态机处理
索引
集群中各个节点都会维护一个本地 Log 用于记录更新操作,还会维护 commitlndex 和lastApplied 两个值,它们是本地Log 的索引值
commitlndex表示的是当前节点已知的、最大的、己提交的日志索引值lastApplied表示的是当前节点最后一条被应用到状态机中的日志索引值。
当节点中的 commitlndex 值大于 lastApplied 值时,会将 lastApplied + 1 ,并将 lastApplied 对应的日志应用到其状态机中。
Leader 还需要了解集群中其他 Follower 节点的这些信息,而决定下次发送 Append Entries 消息中包含哪些日志记录。为此, Leader 节点会维护 nextlndex[]和 matchlndex[]两个数组,这两个数组中记录的都是日志索引值
nextlndex[]记录了需要发送给 Follower 节点的下一条日志的索引值matchlndex[]记录了己经复制给每个Follower 节点的最大的日志索引值
一个数组不就可以表达了吗?
答:不行,
nextIndex用于指示Leader节点将要发送给Follower节点的下一个日志条目的位置,帮助Leader节点推进复制进度;matchIndex用于指示Leader节点已经复制到Follower节点上的最高日志条目的位置,帮助Leader节点确定已经被大多数节点确认的日志条目,可以进行提交
Leader 节点中 matchlndex 大于等于该 Follower 节点对应的 nextlndex 值,那么通过 Append Entries 消息发送从nextlndex 开始的所有日志。之后,Leader节点会检测该 Follower 节点返回的相应响应,
- 如果成功则更新相应该 Follower 节点对应的
nextlndex值和matchlndex值; - 如果因为日志不一致而失败,则减少
nextlndex值重试
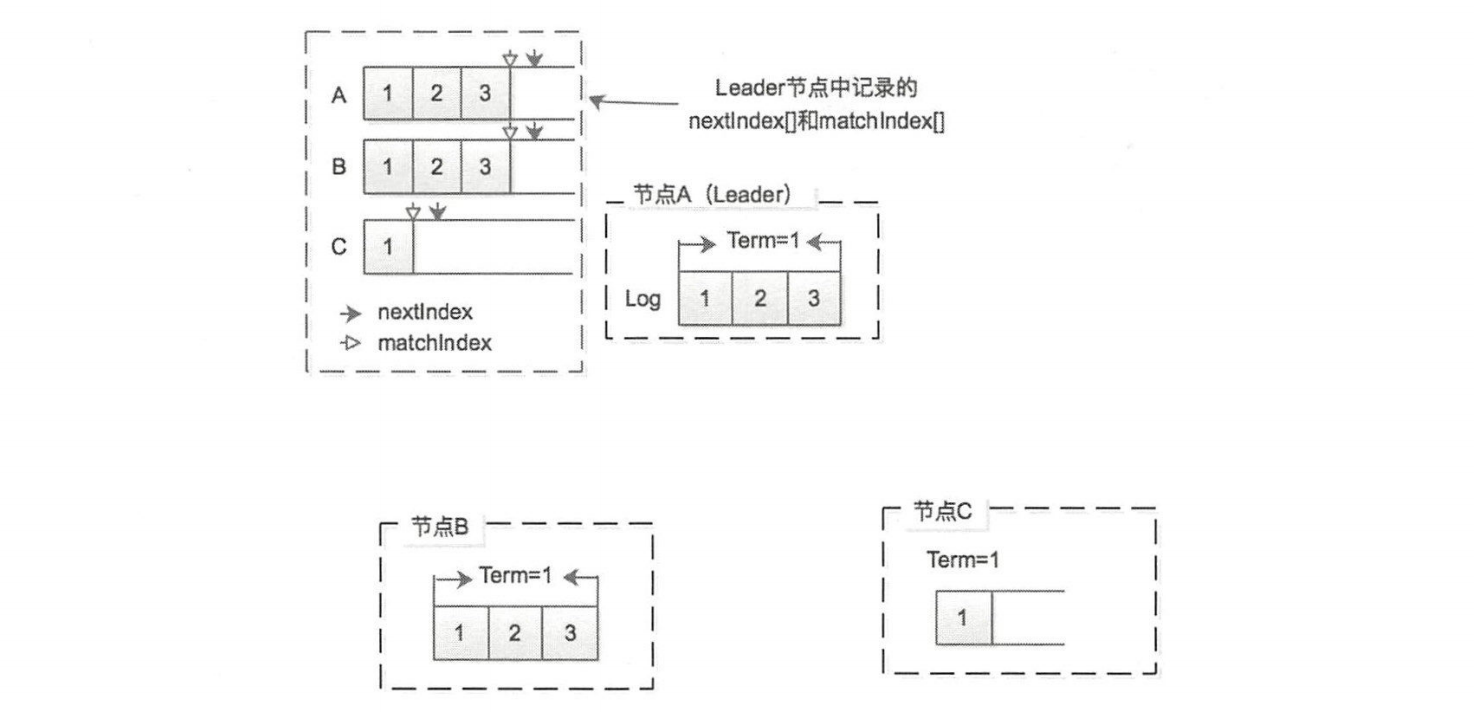
A 作为 Leader 节点记录了 nextlnde 和 matchlndex,所以 A 应该知道向 B 、C 节点发送哪日志
Raft 协议采用批量发送的方式,当B、C 收到 Append Entries 消息后将日志记录到本地 Log 中,然后向 Leader 节点返回追加日志成功的响应,Leader 节点收到响应之后会递增节点对应的nextlndex 、matchlnde 这样,Leader 节点就知道下次发送日志的位置

上面是 Leader 的情况,当 Leader 从 A 切换到 B,B 并不知道 Leader 节点记录 nextlndex、matchlndex 信息 ,所以新 Leader 节点会重置 nextlndex、matchlnd ,其中会将 nextlndex 全部重置为其自身 Log 的最后一条己提交日志的 Index,而 matchlndex 全部重置为 0

新任期中的 Leader 节点向其他节点发送 Append Entrie 消息,拥有了当前 Leader 全部日志记录,会返回追加成功的响应并等后续的日志,而 C 没有 Index=2 Index=3 两条日志,所以追加日志失败的响应, Leader 节点会将 nextindex 前移
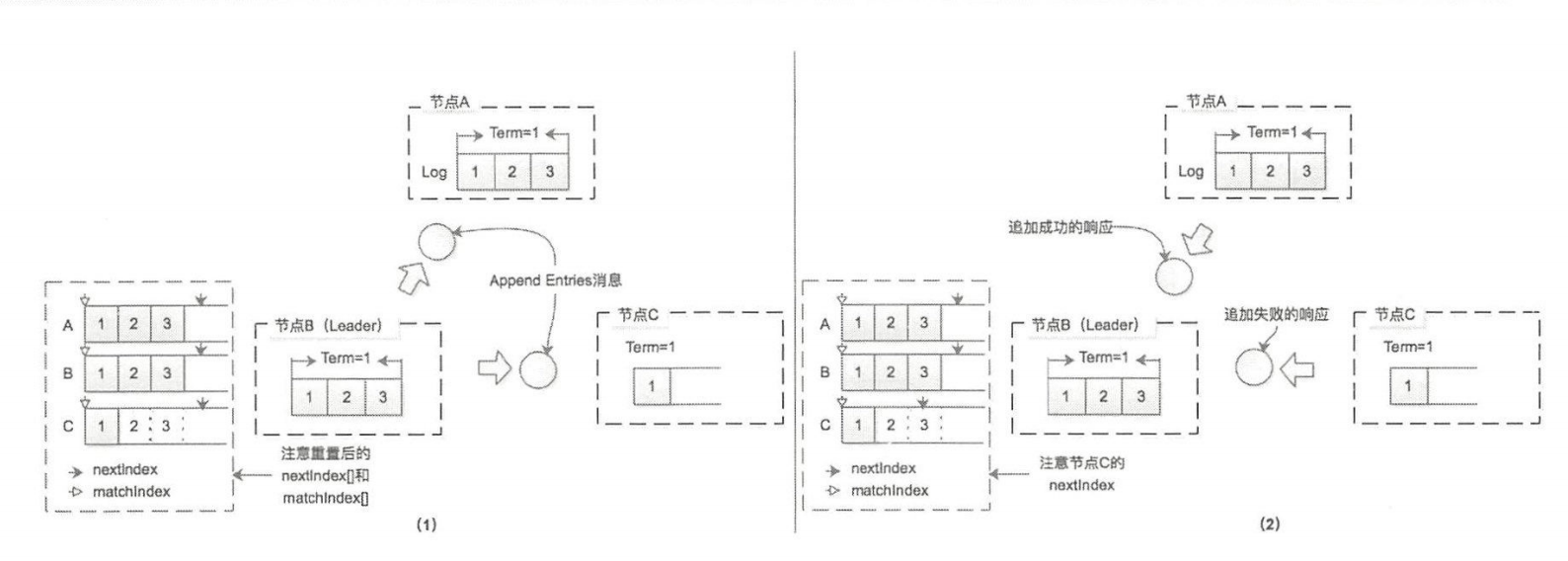
然后新 Leader 会再次尝试发送 append entries 消息,循环往复,不断减小 nextlndex值,直至节点C 返回追加成功的响应,之后就进入了正常追加消息记录的流程
日志判断
那么又是如何判断两条日志是相同的呢,可能两个节点的 log index 相同但是内容并不相同
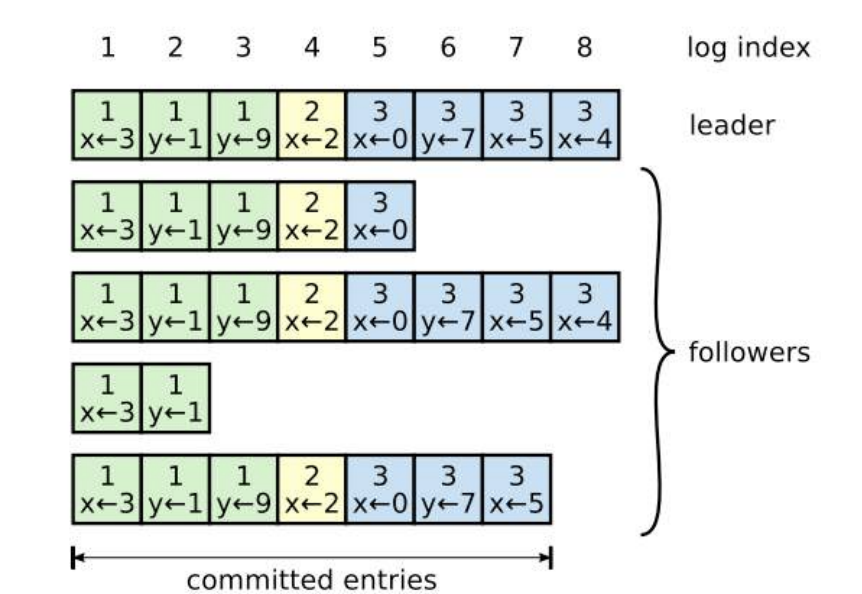
raft 中的每个日志记录都带有 term 和 log index 来唯⼀标识,日志记录具有两个特性
- 如果两条不同节点的某两个日志记录具有相同的 term 和 index 号,则两条记录⼀定是完全相同的 ;
- 如果两条不同节点的某两个日志记录具有相同的 term 和 index 号,则两条记录之前的所有记录也⼀定是完全相同的 ;
以此来判断 leader与 follower 之间的日志是否相同
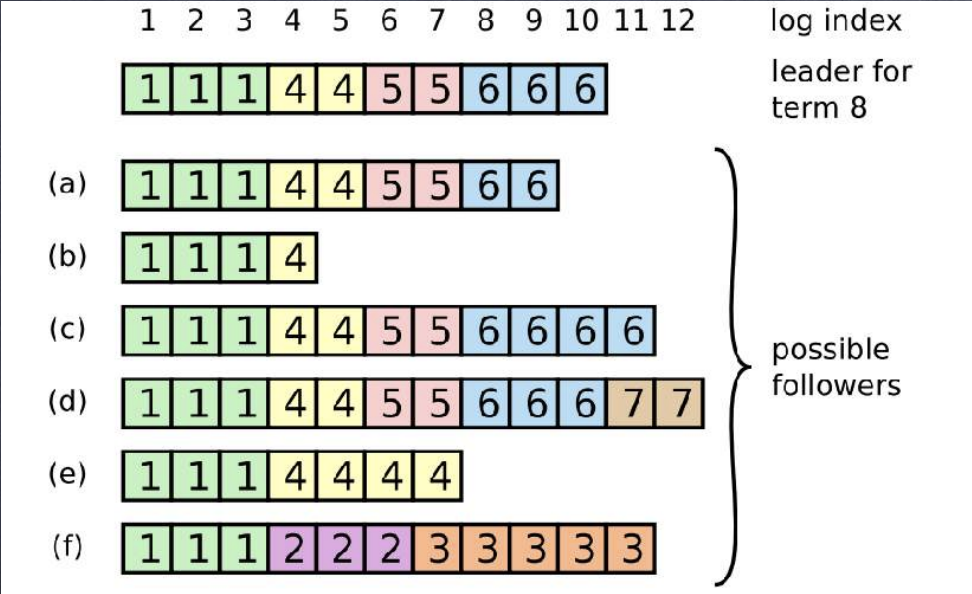
- leader 从来不会覆盖,删除或者修改其日志 ;
- 若 follower 对比其前⼀条 log 不⼀致,则会拒绝 leader 发来的请求. 此时 leader 就将其在
nextIndex[]中的对应值减⼀ - leader 按照自身日志顺序将日志正常复制给 follower,并不断将 nextIndex[] 对应 值 +1,直到对应值 “追上” 自身日志的 index 为⽌;
问题 1:为什么要一个一个对比,而不直接找到对应的位置,批量复制?
答:通过数组存储的是索引,但是日志比较是通过 index 与 term
所以,在选举过程中,Follower 节点还需要比较该 Candidate 节点的日志记录与自身的日志记录,拒绝那些日志没有自己新的 Candidat 节点发来的投票请求,确保将选票投给包含了全部己提交(Commited)日志记录的 Candidate 节点
Raft 协议通过较两节点日志中的最后一条日志记录的索引值和任期号,以决定谁的日志比较新
- 首先比较最后一条日志记录的任期号,如果最后的日志记录的任期号不同,那么任期号大的日志记录比较新:
- 如果最后一条日志记录的任期号相同,那么日志索引较大的比较新
复制异常
场景1:两个Follower 节点不可用,Leader 如何处理请求
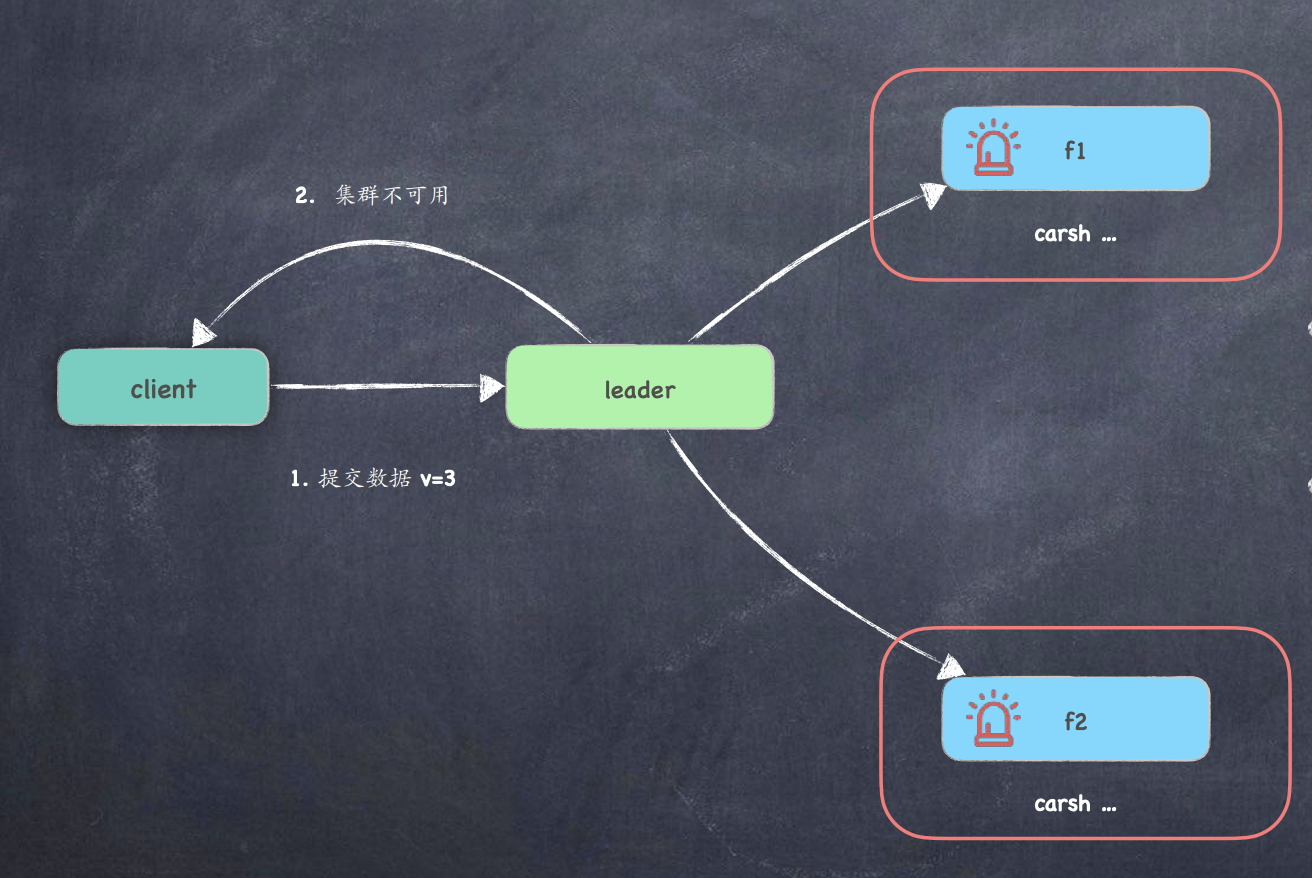
-
leader 通过⼼跳已知 follower 已挂, 则直接返回错误 ;
-
leader 不知节点已挂, 同步数据时得知异常; 触发异常触发超时
场景2: 提交给Leader后,发生了crash
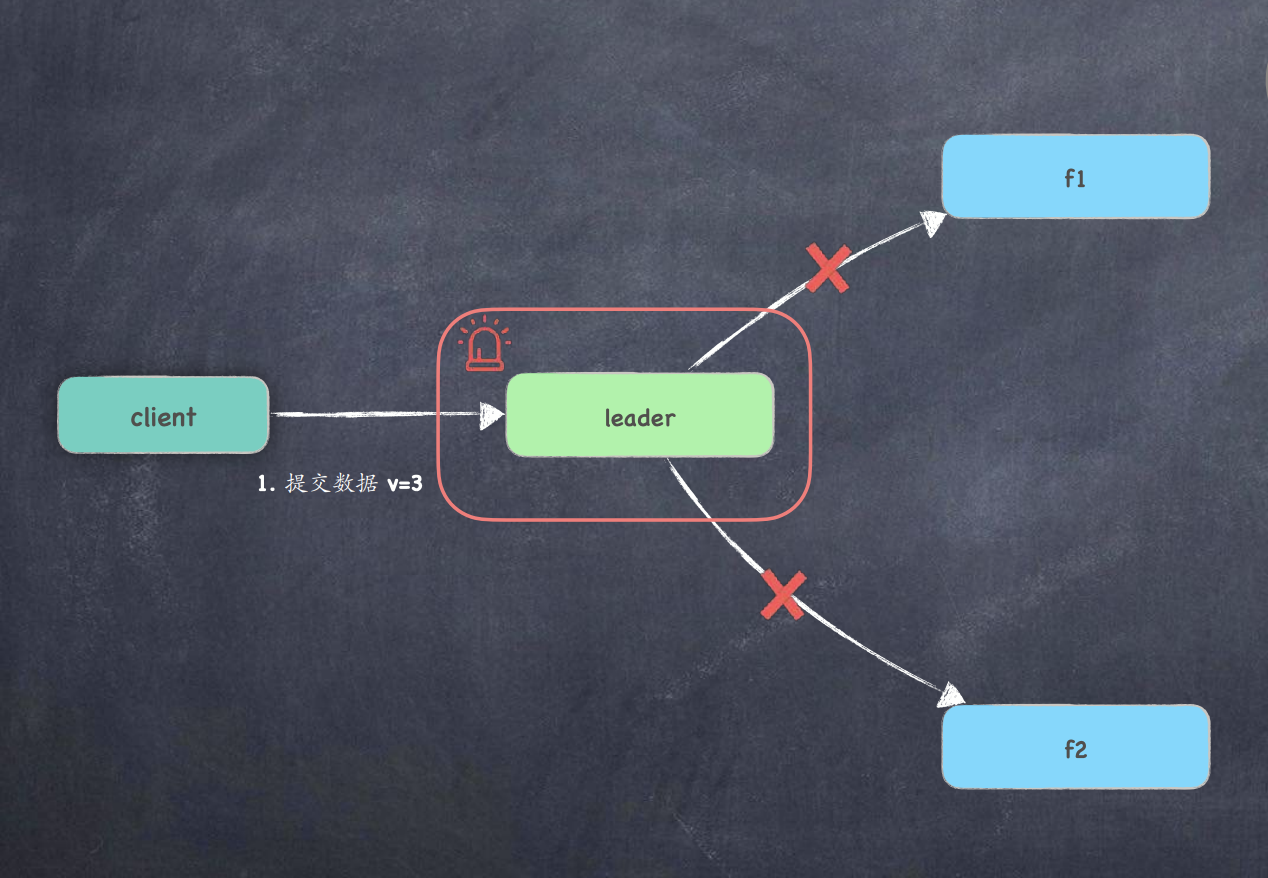
-
leader 本地已记录已提交日志, 重启后强制同步新 leader 数据 ;
-
leader 还没记录未提交日志就crash, 丢了就丢了;
场景3:复制给 follower-1 后, leader就发⽣了 crash ?
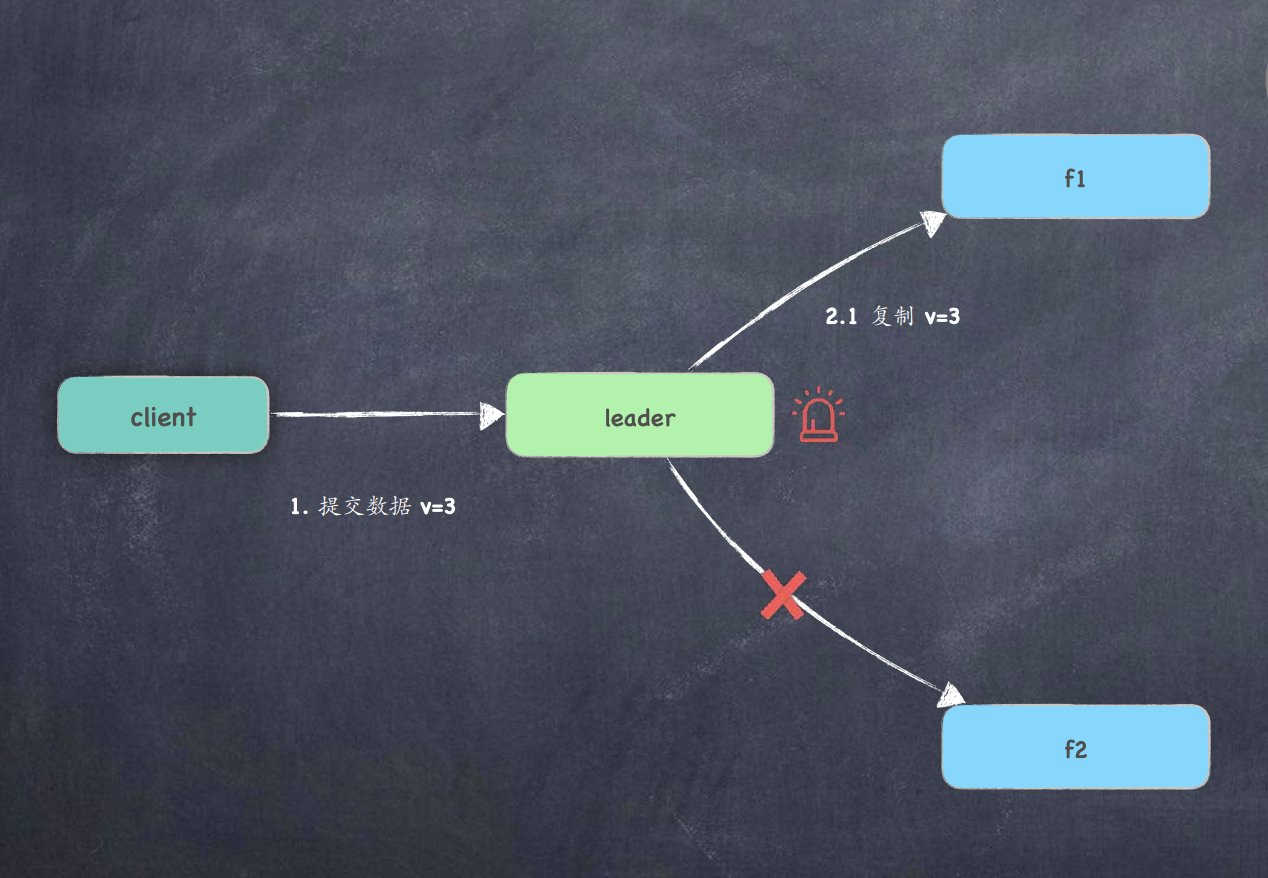
- leader 发⽣了重启,集群触发新的选举 ;
- 由于 follower-1 的数据较新, 那么该节点会晋升 leader ;
- follower-1 会把 uncommited 的 v=3 同步给其他节点 ;
- follower-1 收到其他节点接收确认后, 进⾏提交日志 ;
场景4:follower 返回确认消息时, leader 发⽣了 crash ?
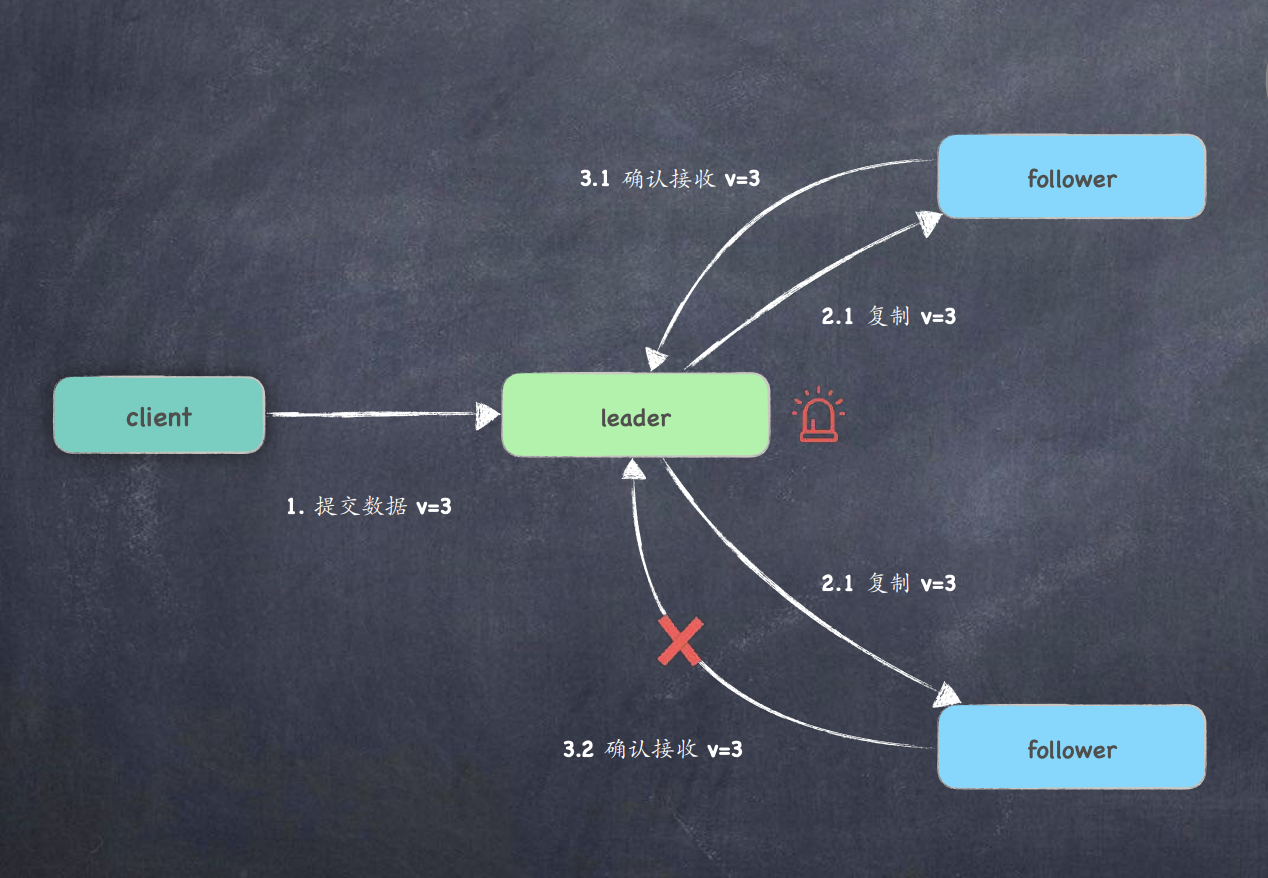
- 三个节点的数据已经⼀致, 都为 uncommited v=3 ; 这时谁当 Leader 都可以 ; 新leader当选后, 需要进⾏同步提交通知 ;
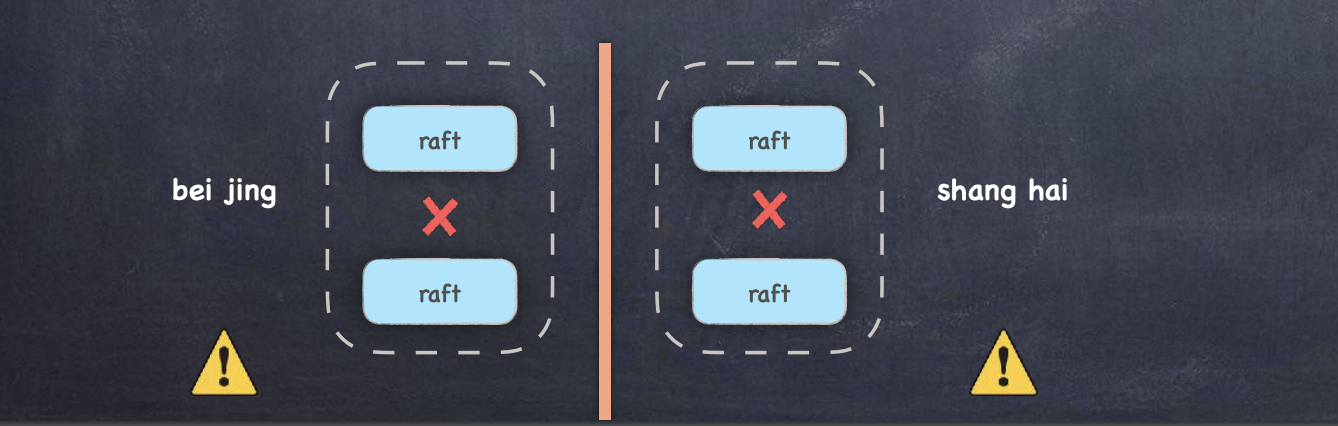
脑裂问题
脑裂问题是原本一个集群,被分成了两个集群,同时出现了两个“大脑”,这就是所谓的“脑裂”现象
出现脑裂的情况:
-
两边都得到过半票数而选举出Leader的情况,不可能出现
-
两边都无法得到过半票数而无法选举出Leader的情况,则服务端会返回客户端集群不可用
-
第三种情况:Leader 与 其他节点通信异常,导致其他节点重新选出 Leader
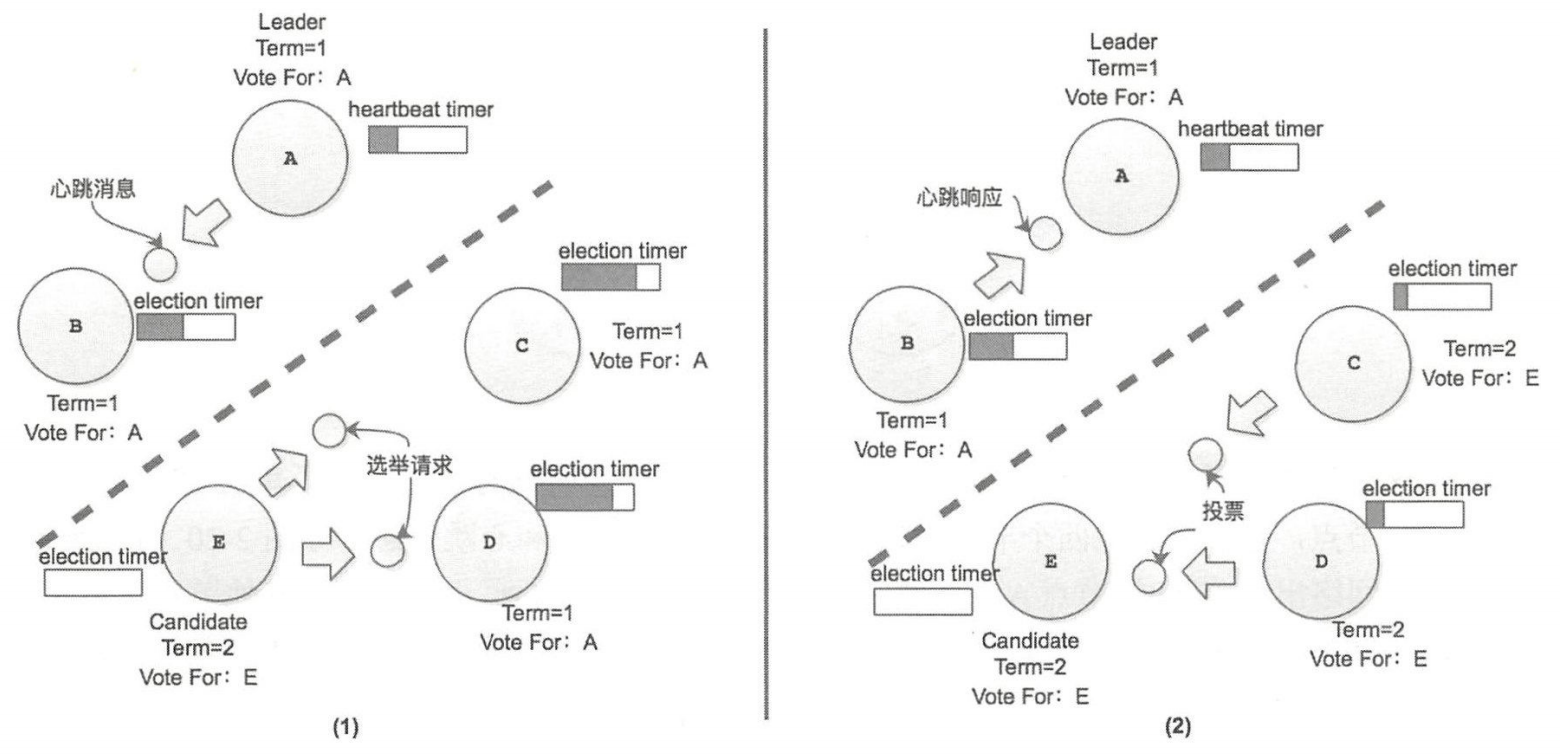
由于 E 能收到超过半数的节点选举票 3 而成为新的 Leader,而 A 、B 会发起 PreVote 因为无法获取半数响应,所以不会触发选举
客户端交互
集群中只有 Leader 点可以处理客户端发来的请求,当 follower 节点收到客户端的请求时,也须将 Leader 信息告知客户端,然后由 Leader 点处理其请求,具体步骤如下:
- 当客户端初次 接到集群时, 会随机挑选个服务器节点进行通信
- 如果客户端第一次挑选的节点不是 Leader 节点 ,那么该节点会拒绝客户端的请求,并且将它所知道的 Leader 节点的信息返回给客户端。
- 当客户端连接到 Leader 节点之后,即可发送消息进行交互
- 如果在交互过程中 Leader 节点宕机,那么客户端的请求会超时,客户端会再次随挑选集群中的节点,并从步骤2重新开始执行
异常 1:发生脑裂
与节点之间发生网络分区之后,客户端发往节点 A 请求将会超时,这是因为节点 A 无法将请求发送到集群中超过半数的节点 ,该请求相应的日志记录也就无法提交,从而导致无法给客户端返回相应的响应
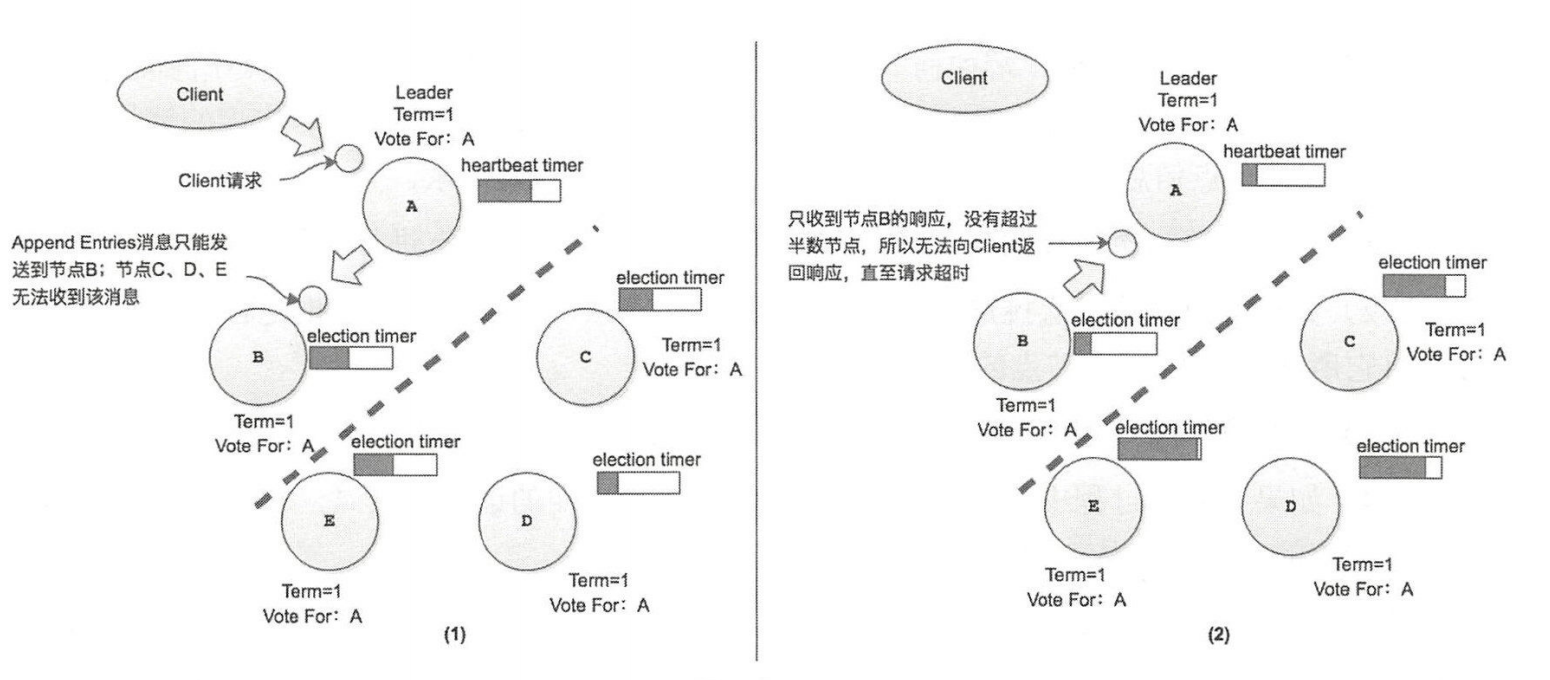
异常 2:Leader 与其他节点通信异常
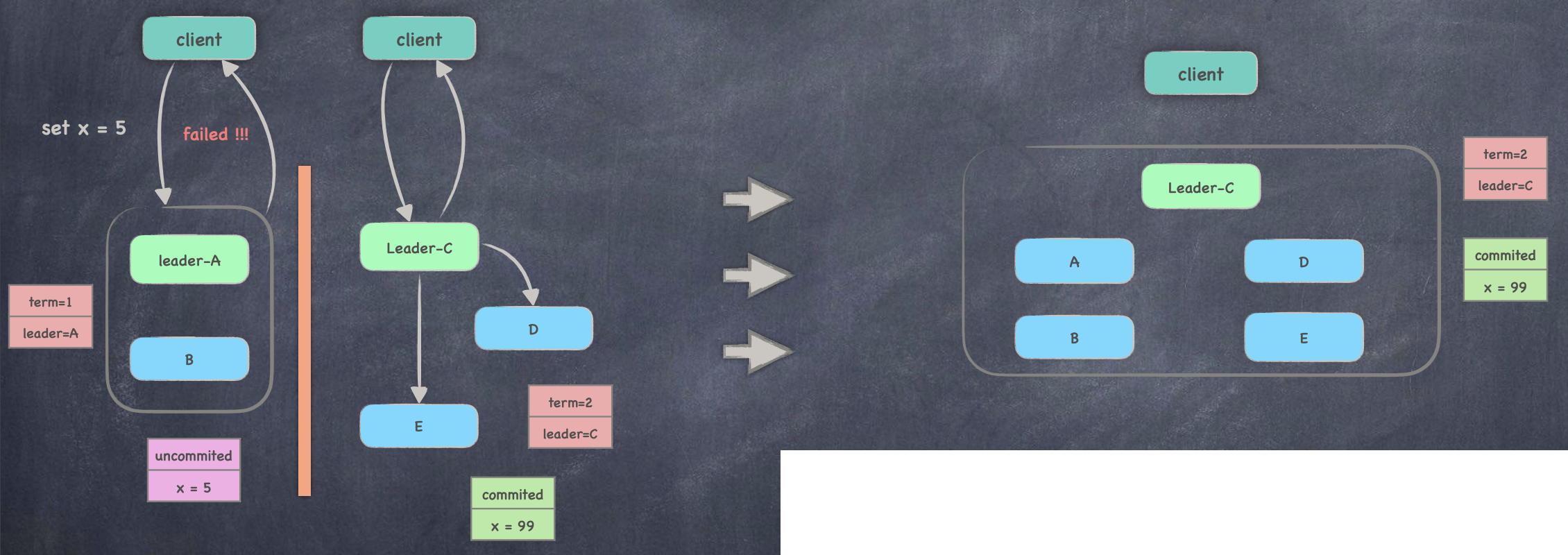
- 由于 leader A ⽆法同步数据到多数节点, 造成 client 写请求失败 ;
- ⽹络分区后 follower c 长时间未收到⼼跳, 则触发选举且当选 ;
- client 按照策略⼀直尝试跟可用的节点进⾏请求 ;
- 当⽹络恢复后, leader A B 将降为 follower, 并且强制同步 Leader C 的数据 ;